
Practical Solutions and Value of MaVEn Framework for MLLMs
Challenges Addressed
The existing Multimodal Large Language Models (MLLMs) face limitations in handling tasks involving multiple images, such as Knowledge-Based Visual Question Answering, Visual Relation Inference, and Multi-image Reasoning.
Solution Overview
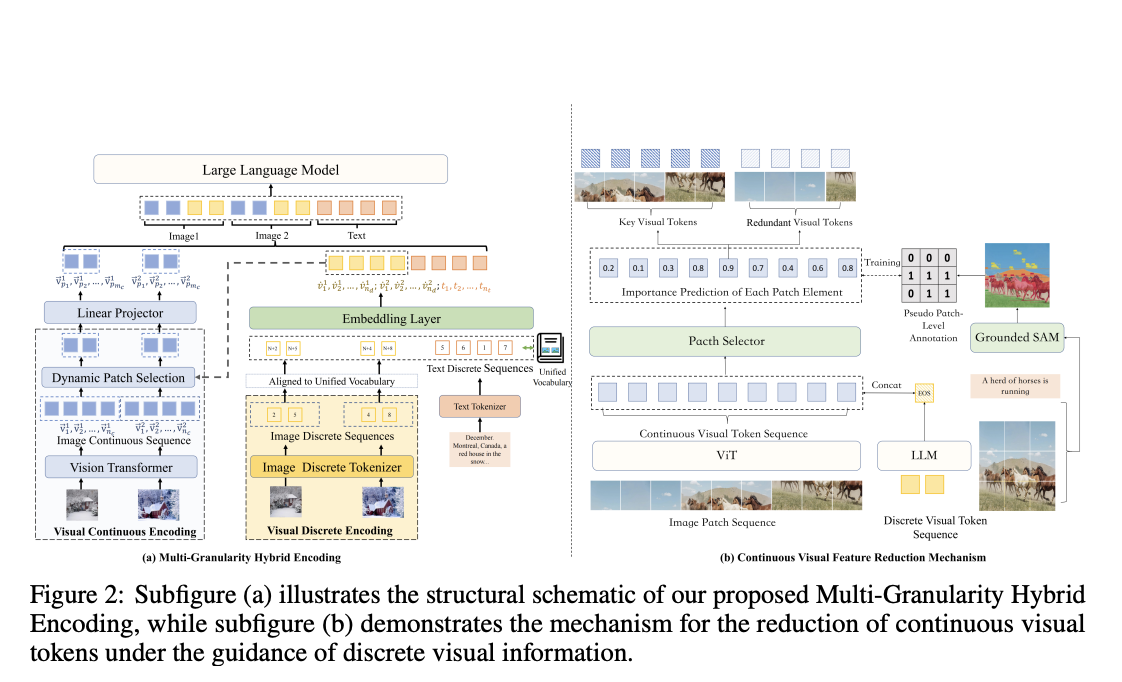
MaVEn is a multi-granularity visual encoding framework designed to enhance the performance of MLLMs in reasoning across numerous images by integrating information from discrete visual symbol sequences and continuous representation sequences.
Key Features
- Discrete Visual Symbol Sequences: Extract semantic concepts from images to facilitate alignment and integration with textual data.
- Sequences for Continuous Representation: Simulate fine-grained characteristics of images to retain specific visual details.
- Dynamic Reduction Method: Manages lengthy continuous feature sequences in multi-image scenarios to optimize processing efficiency.
Benefits
- Enhances MLLMs’ capability to comprehend and process information from various images coherently.
- Improves performance in multi-image reasoning scenarios without sacrificing accuracy.
- Offers flexibility and efficiency in various visual processing applications, including single-image benchmarks.
AI Implementation Advice
Evolve your company with AI by leveraging MaVEn to redefine your way of work. Identify automation opportunities, define KPIs, select an AI solution, and implement gradually to stay competitive in the market.
Connect with Us
For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com. Stay tuned on our Telegram or Twitter for more information.


























