Enhancing AI Model Deployment with MatMamba
Introduction to the Challenge
Scaling advanced AI models for real-world use typically requires training various model sizes to fit different computing needs. However, training these models separately can be costly and inefficient. Existing methods like model compression can worsen accuracy and require extra data and training.
Introducing MatMamba
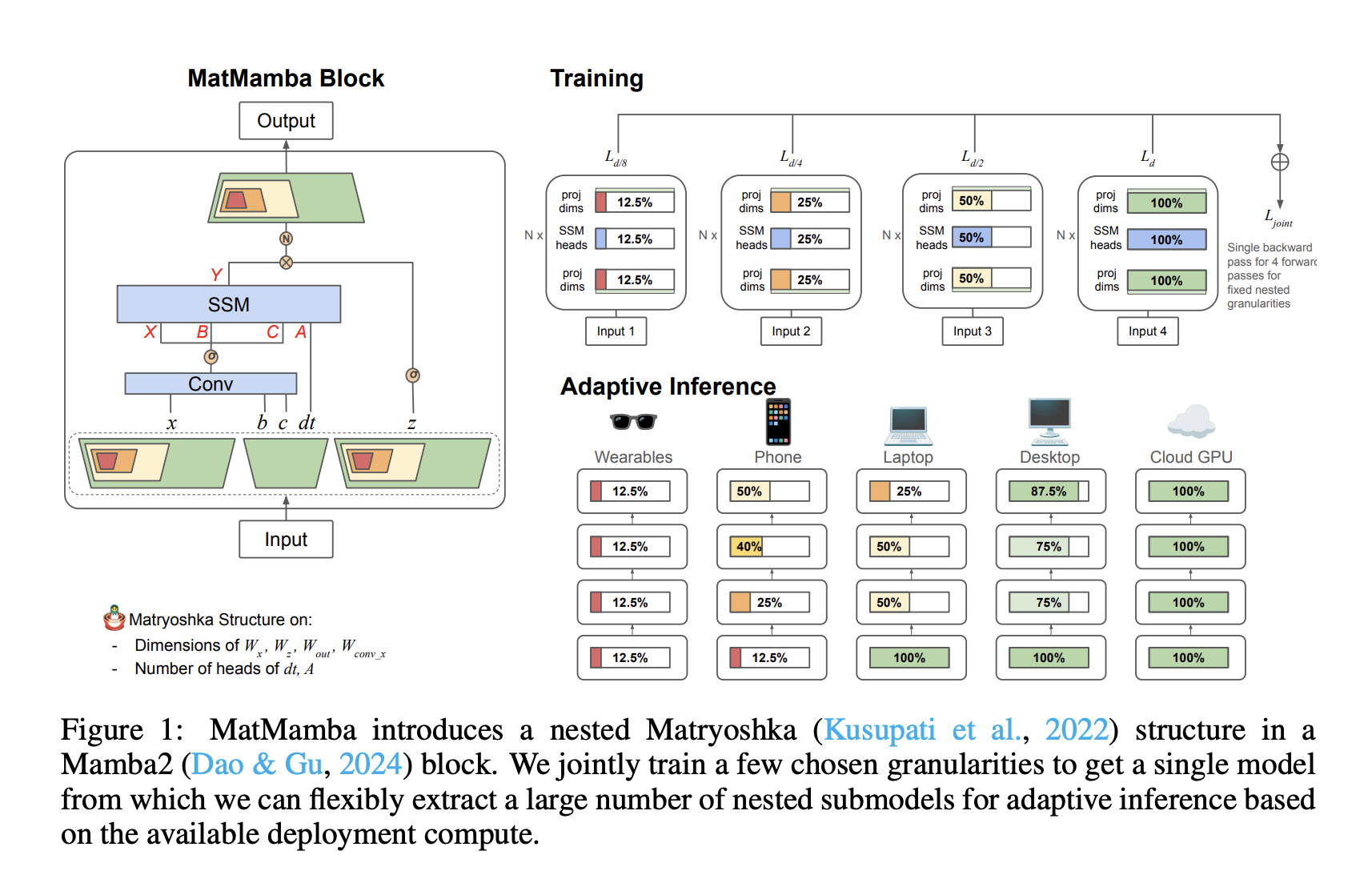
Researchers from Scaled Foundations and the University of Washington have developed a new model called MatMamba. This model builds on Mamba2 and uses a unique nested structure—similar to Russian nesting dolls. This approach allows a single large model to include multiple smaller models inside it, making deployment flexible without the need for separate training.
Key Features and Benefits
– **Adaptive Inference**: MatMamba can adjust according to available computing resources, which is beneficial for large-scale tasks.
– **Various Model Sizes**: The trained models range from 35 million to 1.4 billion parameters, providing options for different deployment scenarios.
– **Efficiency in Training**: Multiple granularities are trained together, optimizing performance while ensuring consistency across smaller submodels.
Versatility Across Applications
MatMamba can be used for various types of models, including those for language, vision, and sound. This makes it adaptable for tasks requiring sequence processing.
Proven Effectiveness
– **Vision Tasks**: In vision applications, MatMamba models performed well on ImageNet, offering efficient inference without sacrificing resolution.
– **Language Tasks**: For language modeling, its models were able to match the performance of traditional models while reducing parameters.
Conclusion and Impact
MatMamba presents a major breakthrough in adaptive inference for state space models. By merging efficient architecture with Matryoshka-style learning, it allows for flexible deployment of large models without losing accuracy. This advancement opens doors for new AI applications, including enhanced decoding methods and cloud-edge solutions.
Stay Connected and Discover More
For further insights, check out the research paper and GitHub. Follow us on Twitter, join our Telegram Channel, and become part of our LinkedIn Group. If you appreciate our work, subscribe to our newsletter and engage with our vibrant ML SubReddit community.
Upcoming Event
Mark your calendars for RetrieveX – The GenAI Data Retrieval Conference on October 17, 2024.
Transform Your Business with AI
Embrace AI to stay competitive. Here’s how:
– **Identify Automation Opportunities**: Find where AI can enhance customer interactions.
– **Define KPIs**: Ensure measurable impacts from your AI initiatives.
– **Select Tailored Solutions**: Choose AI tools that meet your specific needs.
– **Gradual Implementation**: Start with pilot projects to collect data before scaling up.
For AI KPI management support, reach out to us at hello@itinai.com. Stay updated on AI advancements via our Telegram and Twitter channels. Visit itinai.com to explore how AI can revolutionize your sales processes and customer engagement.



