
Understanding Positional Biases in Large Language Models
Assessing Large Language Models (LLMs) accurately requires tackling complex tasks with lengthy input sequences, sometimes exceeding 200,000 tokens. In response, LLMs have improved to handle context lengths of up to 1 million tokens. However, researchers have identified challenges, particularly the “Lost in the Middle Effect,” where models struggle to process information located in the middle of long inputs. Traditional assessments assumed information was concentrated in specific areas, but in reality, it is often scattered, leading to biases based on relative positions.
Introducing LongPiBench
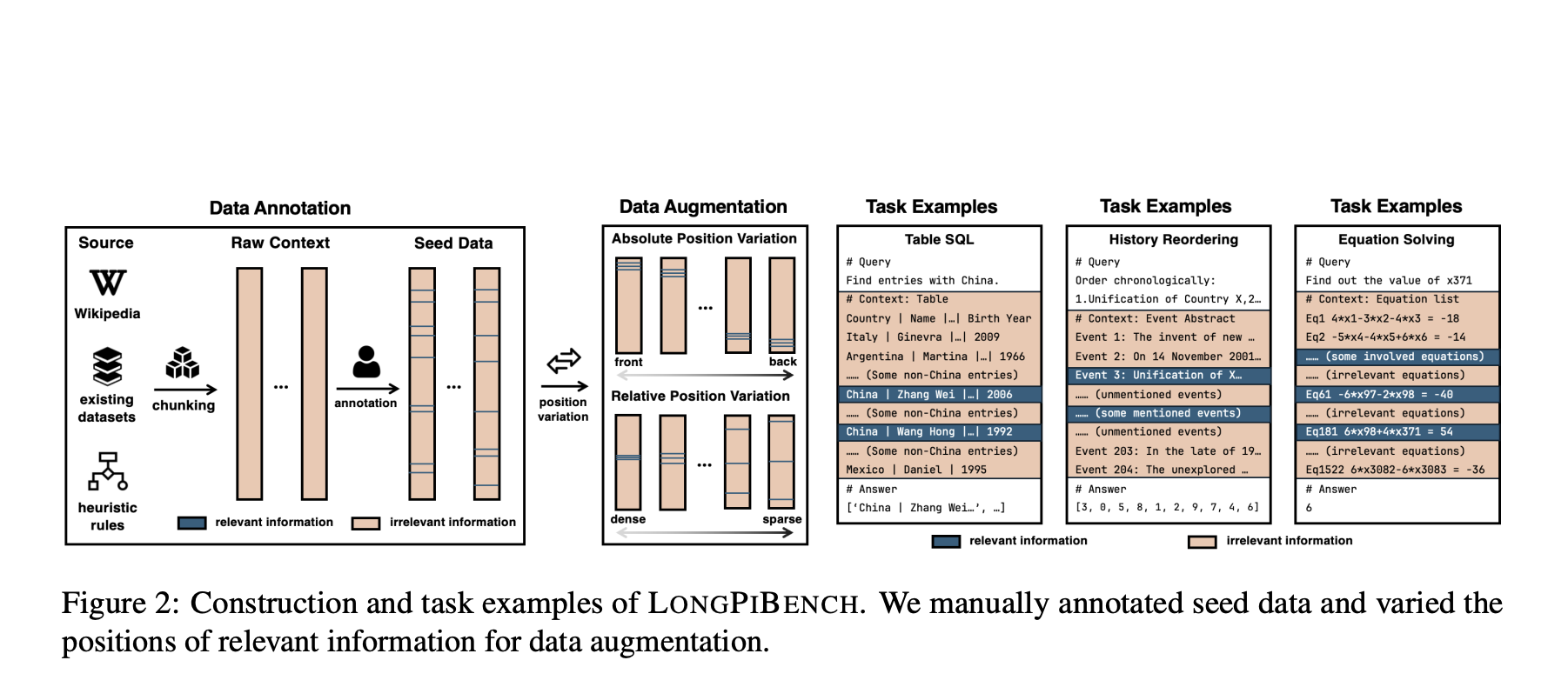
Researchers from Tsinghua University and ModelBest Inc. developed LongPiBench, a benchmark designed to evaluate positional biases in LLMs. This tool assesses both absolute and relative information positions across tasks of varying complexity and token lengths (32k to 256k). LongPiBench includes:
- Three tasks: Table SQL, Timeline Reordering, and Equation Solving.
- Four context lengths: 32k, 64k, 128k, and 256k.
- Sixteen levels of absolute and relative positions.
The evaluation process involves annotating seed examples and varying the positions of relevant information to understand model performance better.
Key Findings from LongPiBench
The research team tested 11 prominent LLMs, discovering that while newer models are somewhat resistant to the “Lost in the Middle Effect,” they still show biases based on the spacing of relevant information. Notable models assessed included Llama-3.1-Instruct, GPT-4o-mini, Claude-3-Haiku, and Gemini-1.5-Flash. Results indicated:
- Top models struggled with timeline reordering and equation solving, achieving only about 20% accuracy.
- Commercial and larger open-source models performed well with absolute positioning but faced significant challenges with relative positioning.
- Relative positioning biases led to a 30% drop in recall rates, even in simple retrieval tasks.
The Importance of Addressing Positional Biases
LongPiBench emphasizes the critical need to address relative positioning biases in modern LLMs. If left unresolved, these biases could significantly hinder the effectiveness of long-text language models in real-world applications.
Explore More and Stay Connected
For further insights, check out the Paper and GitHub. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. If you enjoy our work, subscribe to our newsletter and join our 55k+ ML SubReddit.
Upcoming Live Webinar
Oct 29, 2024: Discover the best platform for serving fine-tuned models with the Predibase Inference Engine.
Leverage AI for Your Business
To stay competitive, consider using LongPiBench to enhance your AI capabilities:
- Identify Automation Opportunities: Find key customer interaction points that can benefit from AI.
- Define KPIs: Ensure your AI initiatives have measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with a pilot project, gather data, and expand AI usage wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights into leveraging AI, follow us on Telegram or Twitter.
Discover how AI can transform your sales processes and customer engagement at itinai.com.


























