
Introduction to Open-Vocabulary Object Detection
Open-vocabulary object detection (OVD) allows for the identification of various objects using user-defined text labels. However, current methods face three main challenges:
- Dependence on Expensive Annotations: They require large-scale region-level annotations that are difficult to obtain.
- Limited Captions: Short and context-poor captions fail to describe object relationships effectively.
- Poor Generalization: They struggle to recognize new object categories, focusing too much on individual features instead of understanding the entire scene.
Advancements in OVD Techniques
Many previous approaches have tried to improve OVD by utilizing vision-language pretraining. Models like GLIP, GLIPv2, and DetCLIPv3 use contrastive learning and dense captioning for better object-text alignment. However, they still have significant limitations:
- Single Object Focus: Region-based captions only describe one object, missing the overall scene context.
- Scalability Issues: Training requires vast labeled datasets, making it hard to scale.
- Lack of Comprehensive Understanding: Without a grasp of the full image semantics, detecting new objects is inefficient.
Introducing LLMDet
Researchers from various institutions have developed LLMDet, a new open-vocabulary detector that uses a large language model for training. Key features include:
- New Dataset: GroundingCap-1M includes 1.12 million images with detailed captions, enhancing object detection.
- Dual Supervision: The training combines grounding loss and caption generation loss for better learning efficiency.
- Comprehensive Captions: Long captions describe entire scenes, while short phrases identify individual objects, improving accuracy and generalization.
Training Process
The training consists of two main stages:
- The projector aligns the object detector’s visual features with the language model’s feature space.
- The detector is fine-tuned with the language model using grounding and captioning losses.
Images are annotated with both short and long captions, ensuring a rich understanding of the context. The model uses a Swin Transformer backbone and processes information at two levels: region-level for objects and image-level for context.
Performance and Benefits
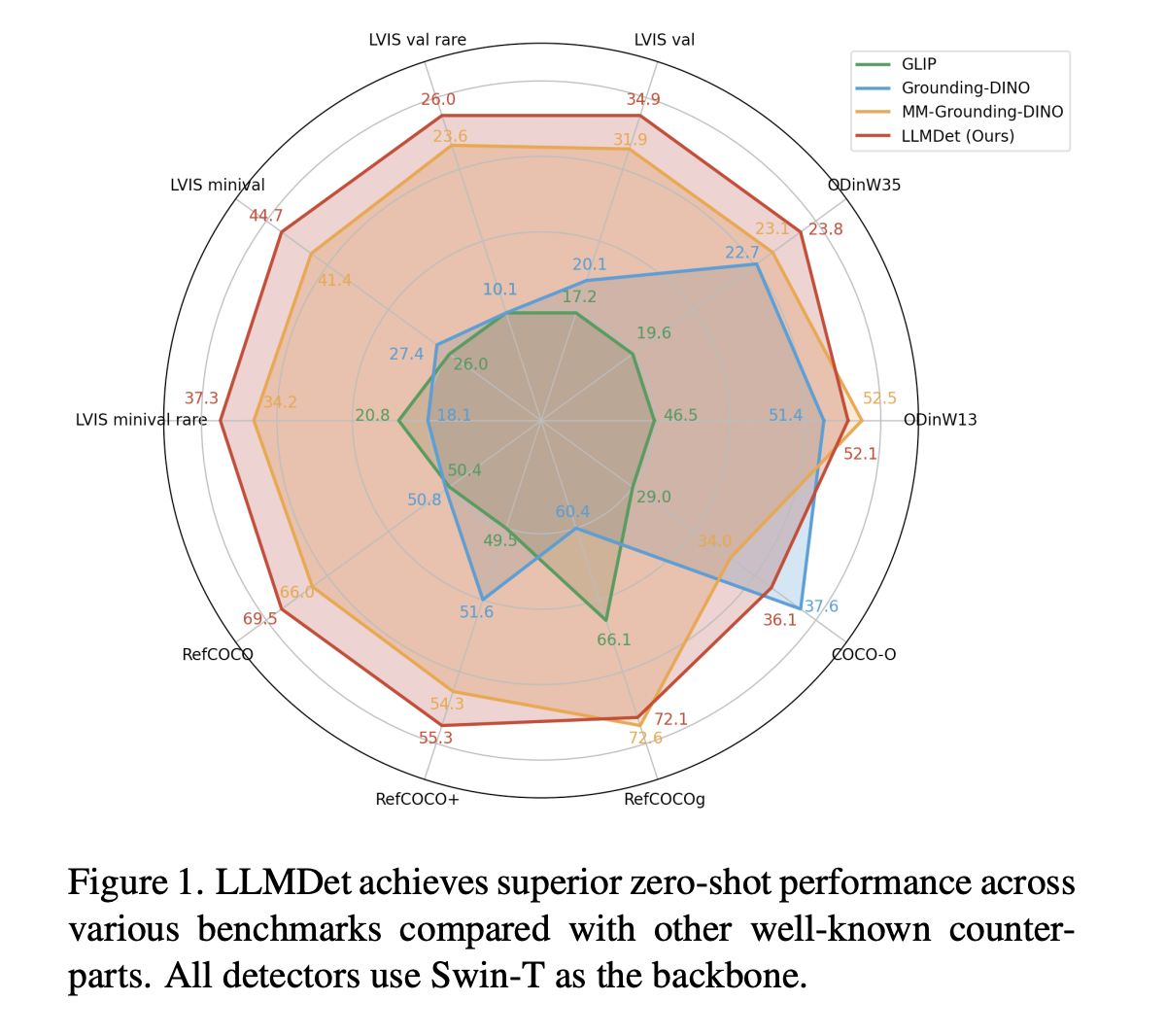
LLMDet achieves state-of-the-art results across various benchmarks, showing:
- Improved Detection Accuracy: Outperforms previous models by 3.3%–14.3% on LVIS, especially for rare classes.
- Better Zero-Shot Transferability: Shows enhanced performance on ODinW across different domains.
- Robustness: Performs well under natural variations, confirming its adaptability.
Combining image-level captioning with region-level grounding significantly boosts performance, particularly for rare objects. This integration also enhances vision-language alignment, reduces inaccuracies, and improves visual question-answering.
Conclusion
LLMDet offers a scalable and efficient approach to open-vocabulary detection, addressing existing challenges and delivering superior performance. Its integration of vision-language learning enhances adaptability and multi-modal interactions, showcasing the potential of language-guided supervision in object detection.
Get Involved
Explore the research paper for more details. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Don’t miss out on our thriving 75k+ ML SubReddit.
Transform Your Business with AI
Stay competitive by leveraging LLMDet for your AI solutions. Here’s how:
- Identify Automation Opportunities: Find key customer interaction points for AI benefits.
- Define KPIs: Measure the impact of your AI initiatives on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, reach out to us at hello@itinai.com. Stay updated on AI insights via our Telegram or Twitter.
Enhance Your Sales and Customer Engagement
Discover innovative AI solutions at itinai.com.
























