
Introduction to TxT360: A Revolutionary Dataset
In the fast-changing world of large language models (LLMs), the quality of pre-training datasets is crucial for AI systems to understand and generate human-like text. LLM360 has launched TxT360, an innovative pre-training dataset with 15 trillion tokens. This dataset is notable for its diversity, scale, and thorough data filtering, making it one of the most advanced open-source datasets available.
A Dataset Built on New Foundations
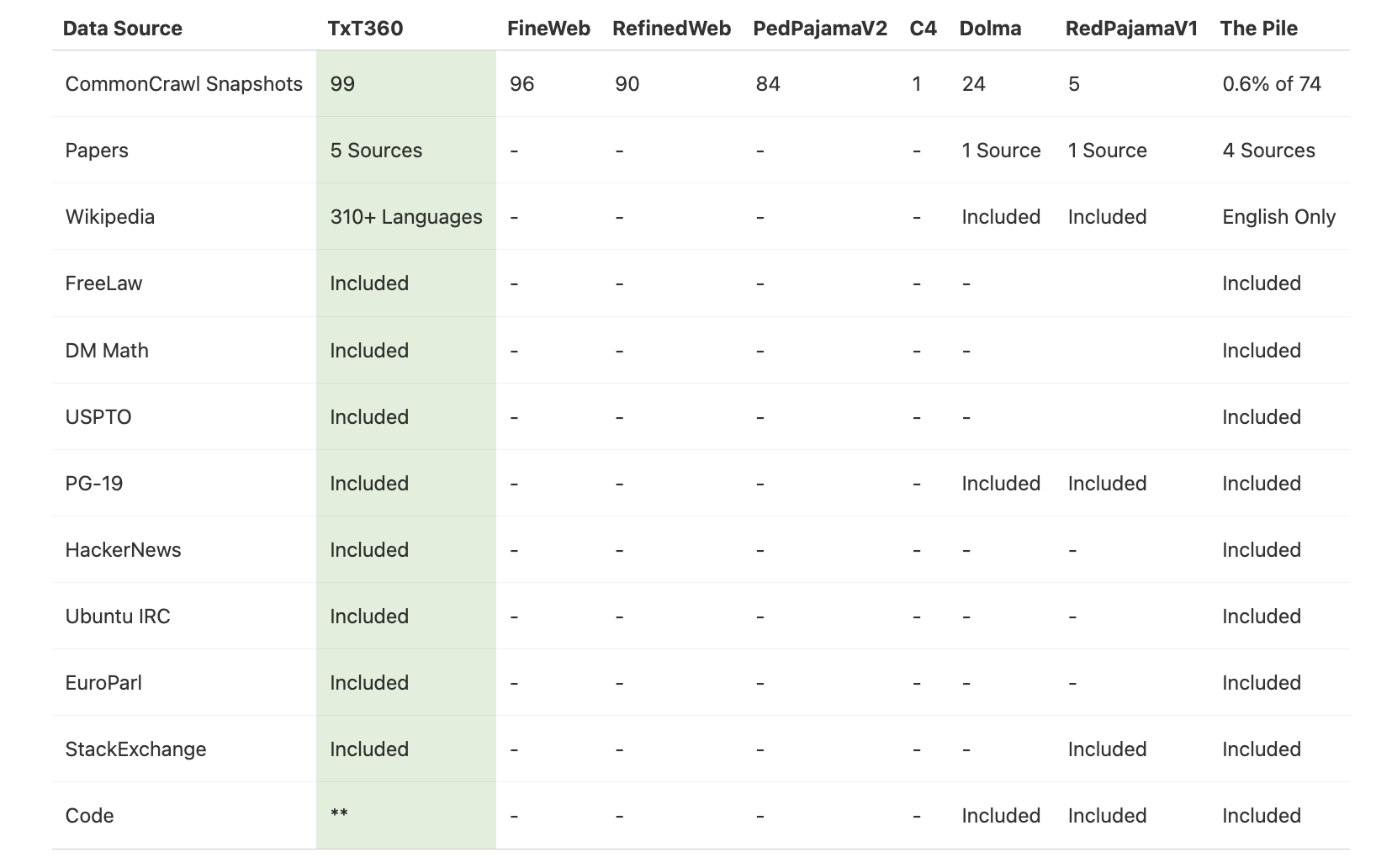
TxT360 stands out by incorporating new sources like FreeLaw (legal texts), PG-19 (a collection of books), scientific papers, and Wikipedia. This combination creates a richer dataset that enhances the capabilities of future LLMs.
From Common Crawl to Clean Data
The development of TxT360 started with Common Crawl, a publicly available web scrape. However, to meet high standards, LLM360 undertook a detailed filtering process:
- Text Extraction: Clean and coherent text was extracted from noisy web data.
- Language Filtering: Non-English content was removed for consistency.
- URL Filtering: Low-value sources were eliminated, including spammy sites.
- Repetition Removal: Efforts were made to remove repeated lines and paragraphs.
- Document and Line-Level Filtering: Heuristics ensured only quality documents remained.
As a result, 97.65% of the original data was filtered out, leaving only high-quality text for robust language models.
Global Deduplication
To ensure quality, LLM360 used two methods for deduplication: exact deduplication with a Bloom filter and fuzzy deduplication with a MinHash algorithm. This approach ensured unique content, avoiding repetitive learning.
High-Quality Sources
After filtering, LLM360 included carefully selected high-quality sources, such as scientific papers, legal documents, classic literature, and curated Wikipedia entries. Each source was processed to maintain data integrity and quality, enabling language models to cover a wide range of topics effectively.
TxT360: A New Era for Open-Source AI
The launch of TxT360 represents a major advancement in AI and natural language processing (NLP) research. LLM360’s careful construction and filtering show that quality and quantity can go hand in hand. With 15 trillion tokens, TxT360 supports the creation of nuanced and intelligent language models.
LLM360’s transparency about their processes sets a new benchmark in the industry. They plan to release their codebase, providing insights into the methodologies behind this impressive dataset.
Stay Connected
For more details about the dataset, visit our website. Follow us on Twitter, and join our Telegram Channel and LinkedIn Group. If you appreciate our work, subscribe to our newsletter and join our 50k+ ML SubReddit community.
Upcoming Event – Oct 17 202
Don’t miss RetrieveX – The GenAI Data Retrieval Conference!
Transform Your Business with AI
To stay competitive, leverage the power of TxT360 in your organization:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI projects have measurable impacts.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights into AI, follow us on Telegram at t.me/itinainews or Twitter @itinaicom.
Discover how AI can transform your sales processes and customer engagement at itinai.com.


























