
Understanding the Fragility of LLM Reasoning Benchmarks
Recent research has highlighted significant weaknesses in the evaluation of reasoning capabilities in large language models (LLMs). These weaknesses can lead to misleading assessments that may distort scientific understanding and influence decision-making in businesses adopting AI technologies. It’s crucial for organizations to be aware of these challenges to ensure that their AI investments yield reliable and actionable insights.
Methodological Challenges in Evaluation
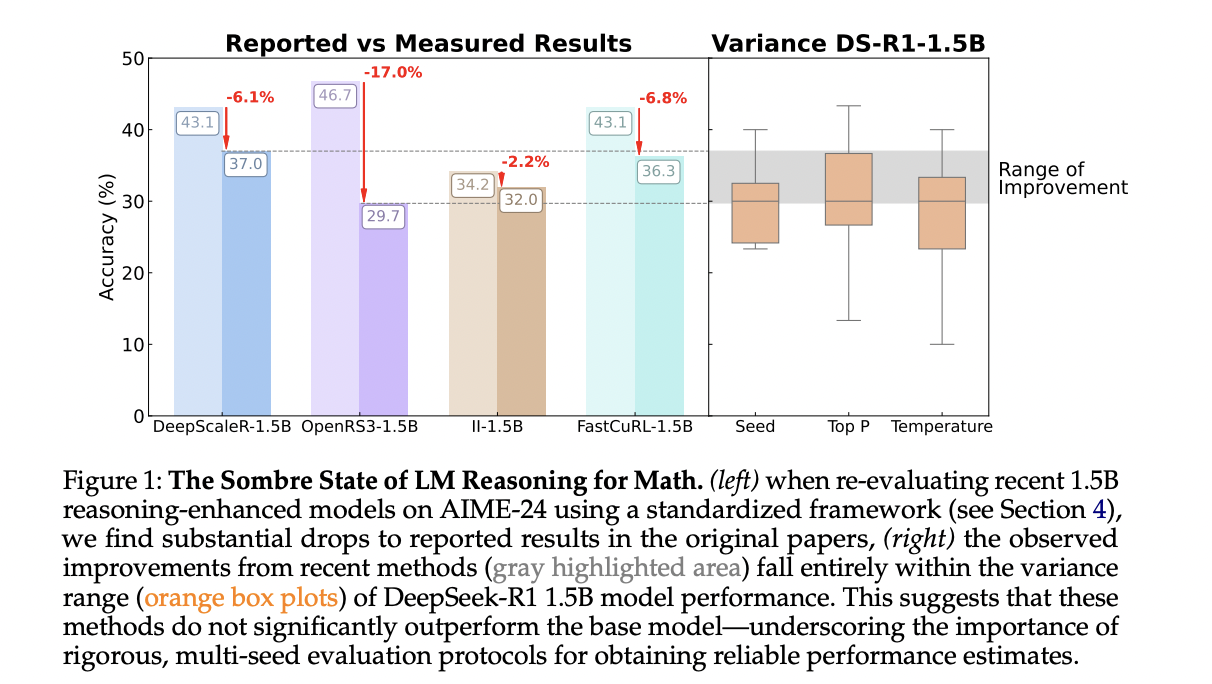
Despite ongoing advancements in AI, particularly in reasoning capabilities of LLMs, evaluation methods remain inconsistent. Many reported improvements in model performance often fail under rigorous testing. For instance, reinforcement learning (RL) techniques, while promising, can lead to performance variances influenced by minor implementation details. A study conducted by researchers from the Tübingen AI Center and the University of Cambridge found that small changes in experimental design greatly affect outcomes, resulting in misleading claims about model performance.
Case Study: Impact of Design Choices
The investigation into reasoning benchmarks revealed that minor factors—such as decoding parameters and random seed variations—could shift performance metrics significantly. For example, on small datasets, a single question could alter performance scores by over 3%, leading to wide fluctuations in reported results. This variance underscores the importance of adopting standardized evaluation practices to ensure reliability.
Current Findings on Model Performance
The research evaluated nine prominent models, including various parameter classes, under consistent hardware and software conditions. It discovered that many RL-trained models did not significantly outperform traditional supervised fine-tuning (SFT) methods. In fact, SFT consistently produced stronger, more generalizable performance across different benchmarks. This finding suggests that businesses should prioritize SFT approaches when developing AI solutions for complex tasks.
Actionable Business Solutions
- Implement Standardized Evaluations: Develop a framework for evaluating AI models that includes consistent hardware and software configurations.
- Focus on Supervised Learning: Prioritize supervised fine-tuning over reinforcement learning when seeking robust AI performance.
- Monitor Evaluation Protocols: Regularly review evaluation methods to ensure they produce reliable results and reflect true model capabilities.
- Start Small: Begin with pilot projects to assess the effectiveness of AI implementations before scaling up.
- Measure KPIs: Establish key performance indicators to assess the impact of AI on business outcomes effectively.
Conclusion
In summary, the landscape of LLM reasoning remains fraught with challenges due to methodological fragility in evaluations. Organizations must adopt rigorous, standardized evaluation practices to differentiate genuine advancements in AI capabilities from artifacts of flawed assessment methodologies. By focusing on proven approaches like supervised fine-tuning and maintaining a vigilant eye on evaluation protocols, businesses can ensure that their AI investments are both effective and trustworthy.
For guidance on integrating AI into your business processes, feel free to contact us at hello@itinai.ru or follow us on social media for the latest updates.

























