
Enhancing Reasoning Models with Length Controlled Policy Optimization
Reasoning language models have improved their performance by generating longer sequences of thought during inference. However, controlling the length of these sequences remains a challenge, leading to inefficient use of computational resources. Sometimes, models produce outputs that are too long, wasting resources, while other times they stop too early, resulting in less effective outcomes.
Challenges in Current Approaches
Current methods to manage output length often degrade performance. Strategies like using special tokens to control length can disrupt the reasoning process. Reasoning tasks require a careful balance between computational efficiency and accuracy, highlighting the need for better length control.
Introducing Length Controlled Policy Optimization (LCPO)
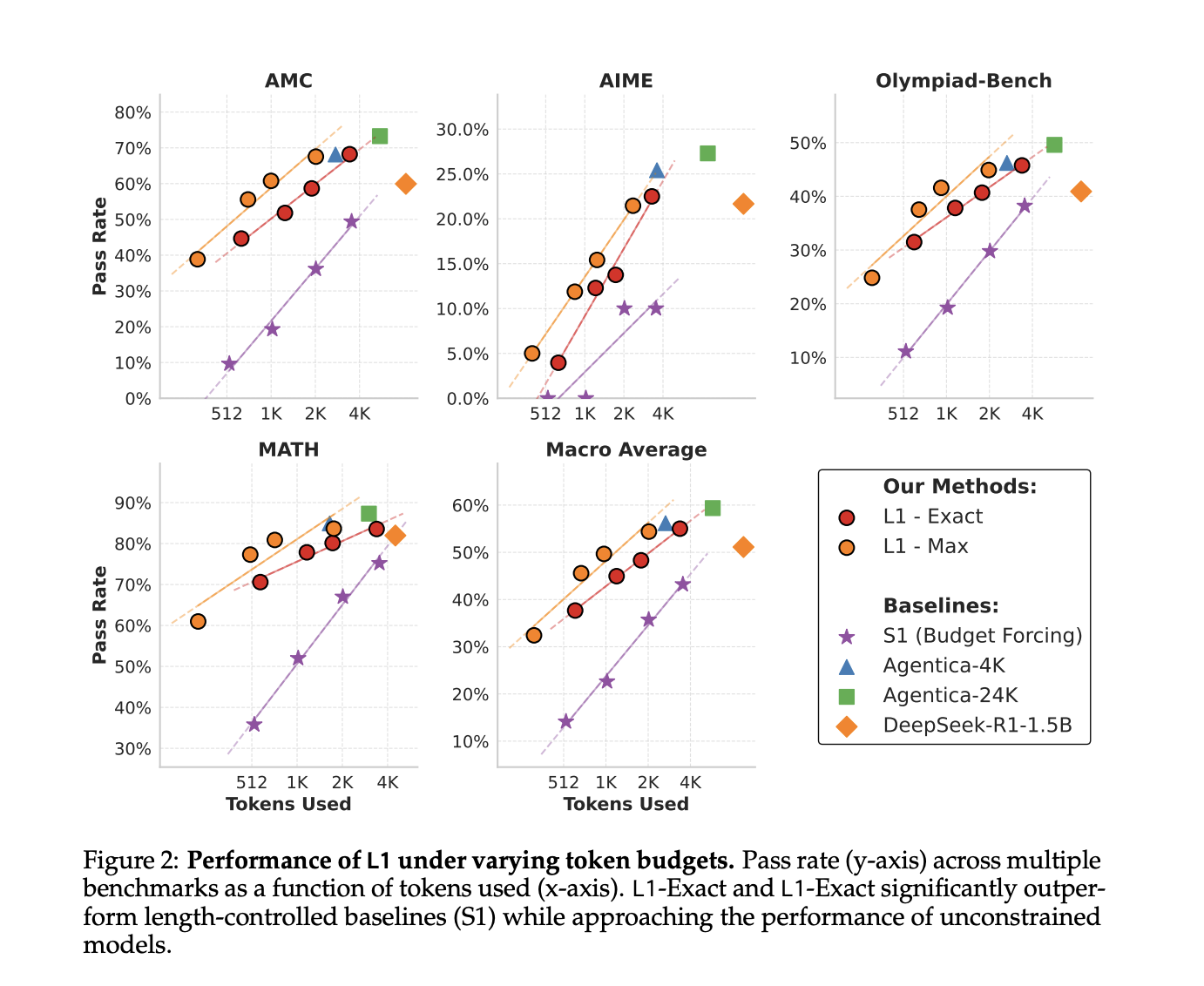
Researchers from Carnegie Mellon University have developed Length Controlled Policy Optimization (LCPO), a reinforcement learning method that enhances reasoning models by ensuring they meet user-specified length constraints. The models trained with LCPO, such as L1, effectively balance computational costs and performance, achieving superior outcomes compared to previous methods.
Key Features of LCPO
LCPO allows for precise control over reasoning length by conditioning the model on a target length provided in the prompt. The training process uses a reward function that balances accuracy with adherence to length constraints, resulting in two variants: L1-Exact, which strictly matches the target length, and L1-Max, which allows for some flexibility while prioritizing correctness.
Performance Benefits
The L1 model demonstrates outstanding performance in length-controlled text generation across various benchmarks, consistently outperforming baseline models. Compared to earlier methods, L1 achieves significant improvements in reasoning tasks, showcasing its ability to adapt reasoning chains effectively.
Conclusion
In summary, LCPO provides a scalable and efficient approach to managing the length of reasoning chains in language models. The L1 model trained with LCPO not only meets user-defined length constraints but also excels in accuracy, outperforming larger models at equivalent lengths. This innovative method balances computational cost with performance, making it a valuable tool for businesses looking to enhance their AI capabilities.
Explore Further
For more information, check out the Paper, Model on Hugging Face, and GitHub Page. Follow us on Twitter and join our 80k+ ML SubReddit.
Practical Business Solutions
Explore how artificial intelligence can transform your work processes:
- Identify processes that can be automated.
- Find opportunities in customer interactions where AI can add value.
- Establish key performance indicators (KPIs) to measure the impact of your AI investments.
- Select customizable tools that meet your specific needs.
- Start with a small project, gather effectiveness data, and gradually expand your AI applications.
Contact Us
If you need guidance on managing AI in your business, reach out to us at hello@itinai.ru. Connect with us on Telegram, X, and LinkedIn.


























