
Practical Solutions for Optimizing Large Language Models (LLMs)
Addressing Inference Latency in LLMs
As LLMs become more powerful, their text generation process becomes slow and resource-intensive, impacting real-time applications. This leads to higher operational costs.
Introducing KOALA for Faster Inference
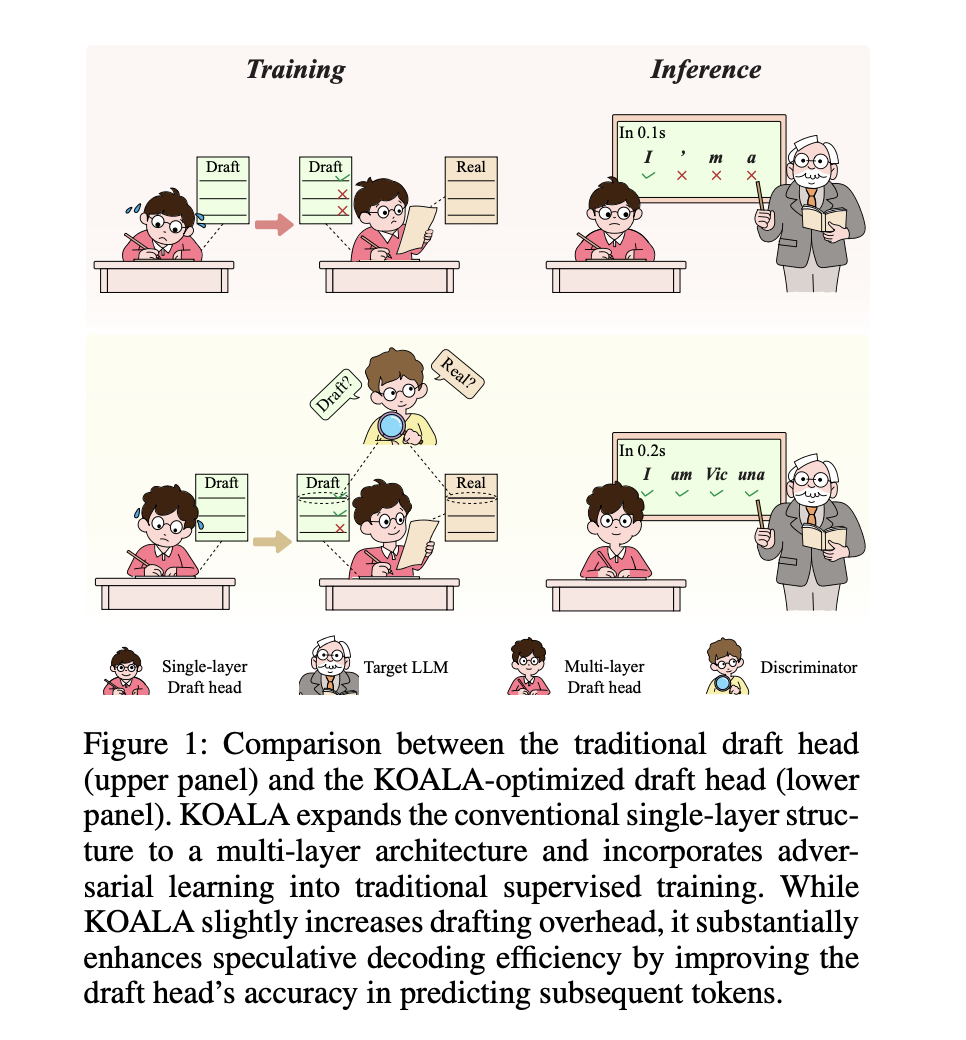
Researchers at Dalian University of Technology, China have developed KOALA, a technique that optimizes the draft head for speculative decoding in LLMs. KOALA reduces latency and improves prediction accuracy, leading to faster inference speeds.
Benefits of KOALA
KOALA enhances the efficiency of speculative decoding, achieving a latency speedup ratio improvement of 0.24x-0.41x and making LLM inference 10.57%-14.09% faster. It introduces a multi-layer structure and adversarial learning to bridge the performance gap between draft heads and target LLMs.
Value of KOALA in Real-World Applications
KOALA offers a promising technique for enhancing the efficiency of LLMs in real-world applications, providing observable improvements in latency speedup ratios.
AI Solutions for Business Transformation
Unlocking AI’s Potential for Business
Discover how AI can redefine your way of work and stay competitive by leveraging KOALA for optimizing LLMs.
Implementing AI for Business Success
Identify automation opportunities, define KPIs, select AI solutions, and implement gradually to evolve your company with AI. Connect with us for AI KPI management advice and continuous insights into leveraging AI.
AI for Sales Processes and Customer Engagement
Explore AI solutions at itinai.com to redefine your sales processes and customer engagement, and discover the potential of AI in transforming your business.

























