
Challenges in Large Language Models (LLMs)
Large Language Models (LLMs) face significant challenges when processing long input sequences. This requires a lot of computing power and memory, which can slow down performance and increase costs. The attention mechanism, essential for these models, adds to the complexity and resource demands.
Key Limitations
- LLMs struggle with sequences longer than their trained context window.
- Performance drops with extended inputs due to inefficient memory use and high attention computation costs.
- Current solutions often involve fine-tuning, which is resource-heavy and needs high-quality datasets.
Proposed Solutions for Long-Context Processing
Various methods have been suggested to improve long-context processing:
- FlashAttention2 (FA2): Reduces memory use but doesn’t solve computational inefficiency.
- Selective Token Attention: Reduces processing load by focusing on important tokens.
- KV Cache Eviction: Removes older tokens but risks losing important context.
- HiP Attention: Moves less-used tokens to external memory but can increase latency.
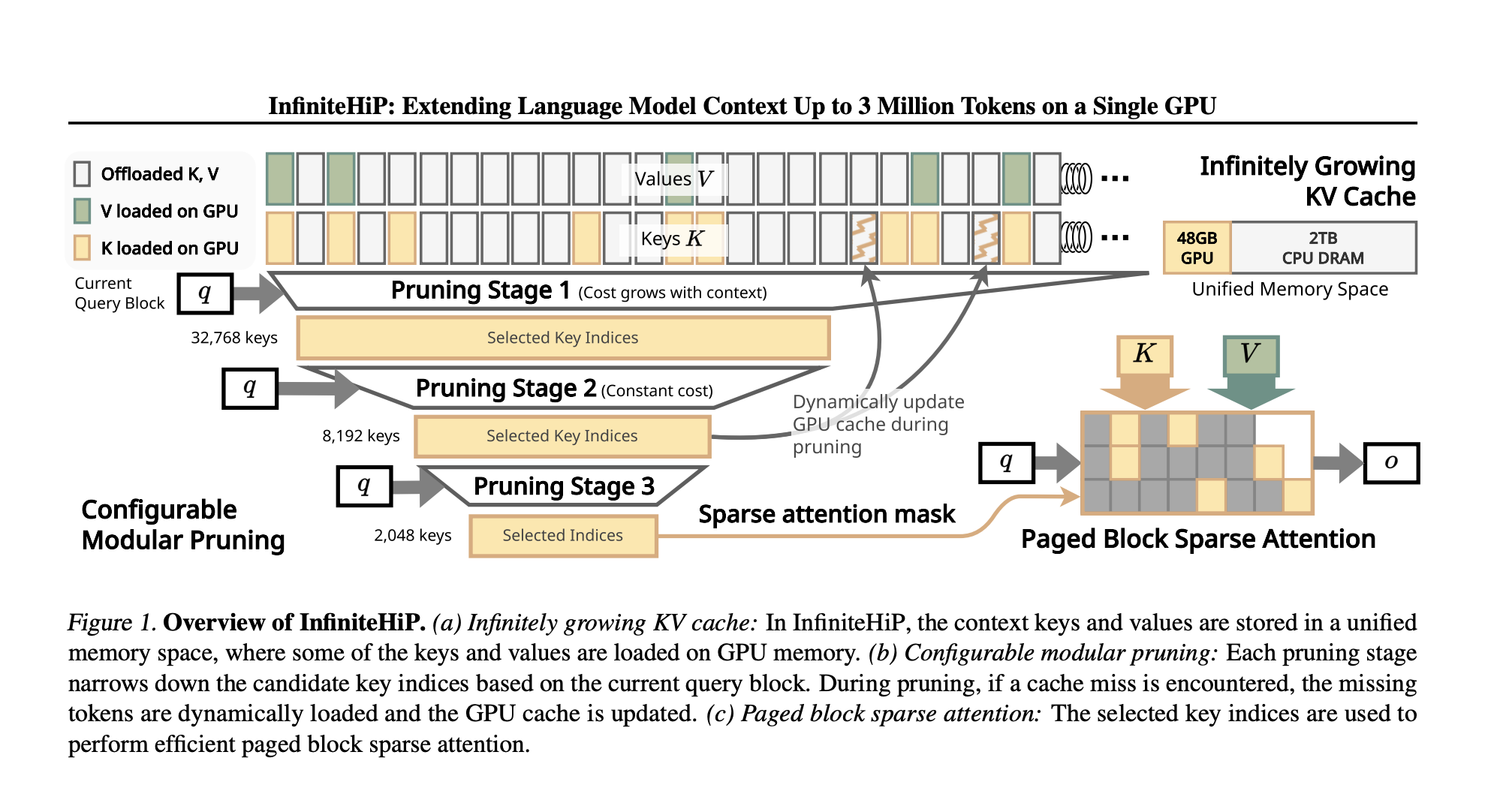
Introducing InfiniteHiP
Researchers from KAIST and DeepAuto.ai have developed InfiniteHiP, a framework that efficiently handles long-context inference while reducing memory issues. Here’s how it works:
Key Features
- Hierarchical Token Pruning: Dynamically removes less relevant tokens, focusing on those that matter most.
- Adaptive RoPE Adjustments: Allows models to handle longer sequences without extra training.
- KV Cache Offloading: Transfers infrequently accessed tokens to host memory for efficient retrieval.
Performance Benefits
InfiniteHiP can process up to 3 million tokens on a 48GB GPU, making it highly scalable. It achieves:
- 18.95× faster attention decoding for one million-token contexts.
- Up to 96% reduction in GPU memory usage.
- 3.2× increased decoding throughput on consumer GPUs and 7.25× on enterprise GPUs.
Conclusion
InfiniteHiP effectively addresses the main challenges of long-context inference. It enhances LLM capabilities through innovative pruning, cache management, and generalization techniques. This breakthrough allows models to process longer sequences efficiently, making it suitable for various AI applications.
Get Involved
Explore the Paper, Source Code, and Live Demo. Follow us on Twitter and join our 75k+ ML SubReddit community.
Transform Your Business with AI
Stay competitive by leveraging InfiniteHiP for your AI needs:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start small, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or @itinaicom.
Discover how AI can enhance your sales processes and customer engagement at itinai.com.

























