
Practical Solutions and Value of Retrieval-Augmented Generation (RAG) in Natural Language Processing
Efficient Information Retrieval and Processing
Retrieval-augmented generation (RAG) breaks down large documents into smaller text chunks, stored in a vector database. This enables efficient retrieval of pertinent information when a user submits a query, ensuring only the most relevant text chunks are accessed.
Practical Applications of Long-Context Embedding Models
The release of jina-embeddings-v2-base-en, with an 8K context length, sparked discussion about practical applications and limitations of long-context embedding models. Research indicates that dense vector-based retrieval systems perform more effectively with smaller text segments, preserving nuanced meanings and leading to more accurate retrieval results in various applications.
Advancements in Text Processing for RAG Systems
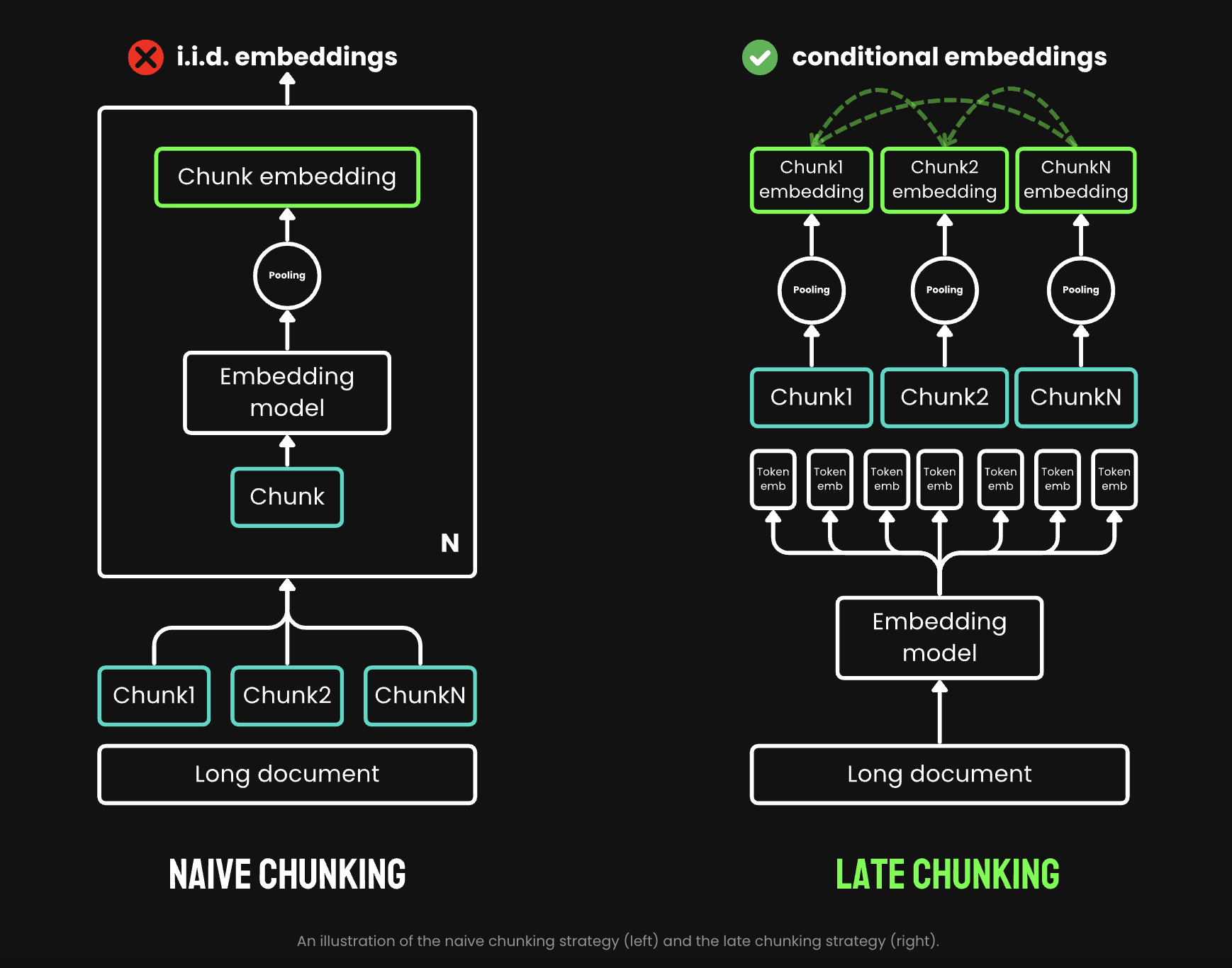
The “Late Chunking” method represents a significant advancement in utilizing the rich contextual information provided by 8192-length embedding models, bridging the gap between model capabilities and practical application needs. This approach aims to demonstrate the untapped potential of extended context lengths in embedding models.
Effective Information Retrieval and Retrieval Benchmarks
Tests using retrieval benchmarks from BeIR consistently showed improved scores for late chunking compared to the naive approach. Late chunking’s effectiveness increases with document length, highlighting its particular value for processing longer texts in retrieval tasks.
AI Solutions for Business Transformation
Identify Automation Opportunities, Define KPIs, Select an AI Solution, and Implement Gradually. Connect with us at hello@itinai.com for AI KPI management advice and continuous insights into leveraging AI.
AI for Sales Processes and Customer Engagement
Discover how AI can redefine your sales processes and customer engagement. Explore solutions at itinai.com.

























