Practical Solutions and Value of JailbreakBench
Standardized Assessment for LLM Security
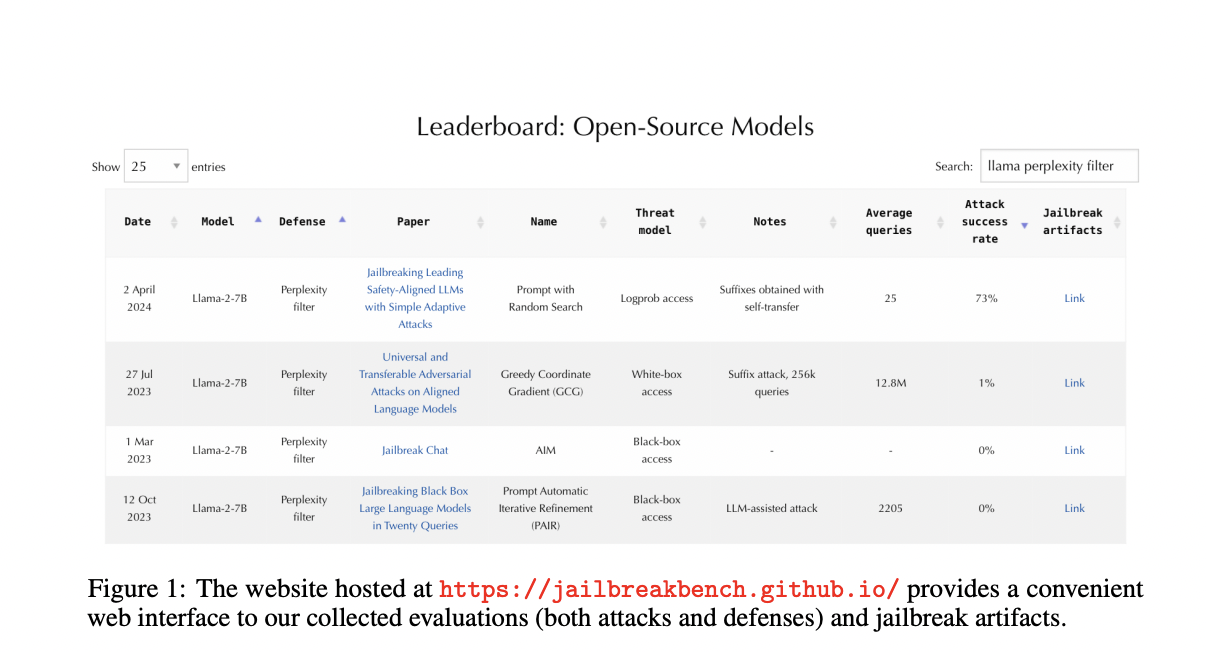
JailbreakBench offers an open-source benchmark to evaluate jailbreak attacks on Large Language Models (LLMs). It includes cutting-edge adversarial prompts, a diverse dataset, and a standardized assessment framework to measure success rates and effectiveness.
Enhancing LLM Security
By utilizing JailbreakBench, researchers can identify vulnerabilities in LLMs, develop stronger defenses, and ensure the ethical use of language models. The platform aims to create more trustworthy and secure language models for sensitive fields.
Transparency and Collaboration
JailbreakBench promotes transparency in research by providing a leaderboard for comparing model vulnerabilities and defense strategies. It encourages collaboration within the research community to address evolving security risks in language models.
























