
Practical Solutions for Deep Reinforcement Learning Instability
Addressing the Challenge
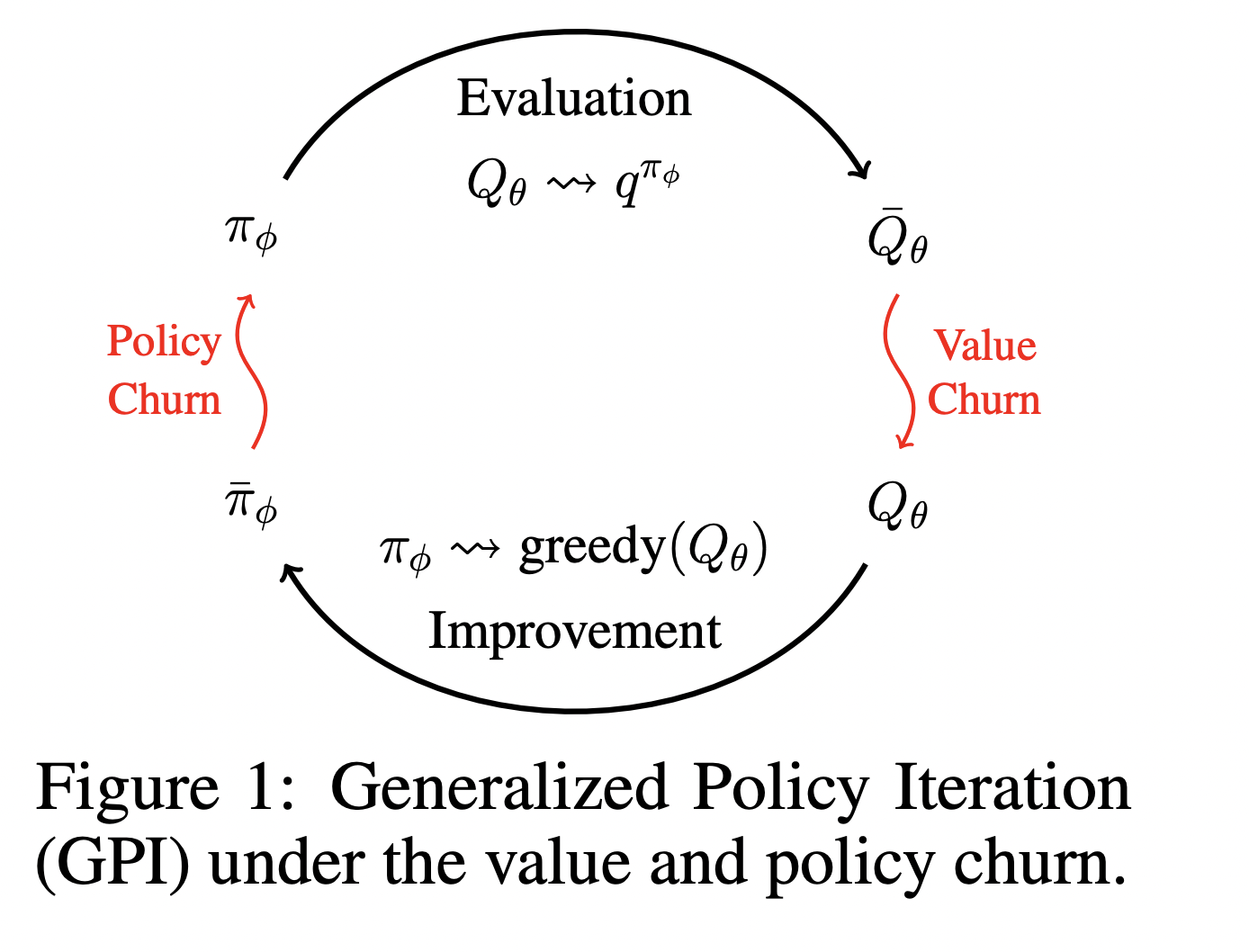
Challenges in Deep Reinforcement Learning (DRL) due to instability caused by churn during training can be tackled effectively with proper solutions. Churn, referring to unpredictable changes in neural network outputs, can lead to inefficient training and poor performance in RL applications like autonomous driving and healthcare.
Introducing CHAIN Method
The CHAIN method reduces churn in DRL by introducing regularization losses during training to control unwanted changes in the network outputs. Regularizing value and policy churn enhances stability and sample efficiency across various RL environments. CHAIN is designed to integrate seamlessly into existing DRL algorithms with minimal modifications, making it a versatile solution for improving learning dynamics.
Key Features of CHAIN
CHAIN introduces two main regularization terms, value churn reduction loss (L_QC) and policy churn reduction loss (L_PC), computed using reference data batches to minimize unwanted changes in the network outputs. By comparing current and previous outputs, the method enhances stability in learning environments while improving sample efficiency.
























