
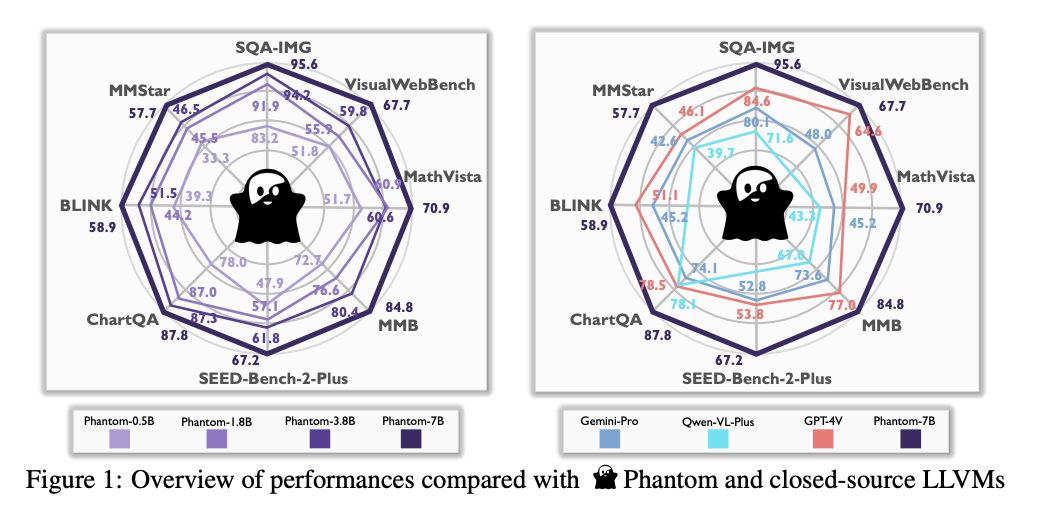
Practical Solutions for Efficient Large Language and Vision Models
Challenge:
Large language and vision models (LLVMs) face a critical challenge in balancing performance improvements with computational efficiency.
Solutions:
– **Phantom Dimension:** Temporarily increases latent hidden dimension during multi-head self-attention (MHSA) to embed more vision-language knowledge without permanently increasing model size.
– **Phantom Optimization (PO):** Combines autoregressive supervised fine-tuning (SFT) with direct preference optimization (DPO) to enhance efficiency while maintaining high performance.
Value:
– **Efficiency:** Enables smaller models to perform at the level of larger models without increasing computational burden.
– **Practicality:** Suitable for real-time applications and resource-limited environments.
– **Performance:** Outperforms larger models in image understanding, chart interpretation, and mathematical reasoning tasks.
Conclusion:
The Phantom LLVM family introduces innovative solutions to enhance the efficiency of large vision-language models, making them feasible for deployment in various scenarios.
**For more information, check out the Paper and GitHub.**























