
Enhancing Efficiency in Deep Learning through Weight Quantization
Introduction
In today’s competitive landscape, optimizing deep learning models for deployment in environments with limited resources is crucial. Weight quantization is a key technique that reduces the precision of model parameters, typically from 32-bit floating-point values to lower bit-width representations. This process results in smaller models that can operate more efficiently on constrained hardware.
Understanding Weight Quantization
Weight quantization involves converting the weights of a neural network to lower precision formats. This not only reduces the model size but also enhances inference speed, making it suitable for applications in mobile devices and edge computing.
Case Study: ResNet18 Model
In this tutorial, we will demonstrate weight quantization using PyTorch’s dynamic quantization technique on a pre-trained ResNet18 model. The process includes:
- Inspecting weight distributions
- Applying dynamic quantization to key layers
- Comparing model sizes
- Visualizing changes in weight distributions
Practical Steps for Implementation
1. Setting Up the Environment
Begin by importing the necessary libraries such as PyTorch and Matplotlib. Ensure that all modules are ready for model manipulation and visualization.
2. Loading the Pre-trained Model
Load the pre-trained ResNet18 model in floating-point precision and prepare it for evaluation. This sets the stage for applying quantization techniques.
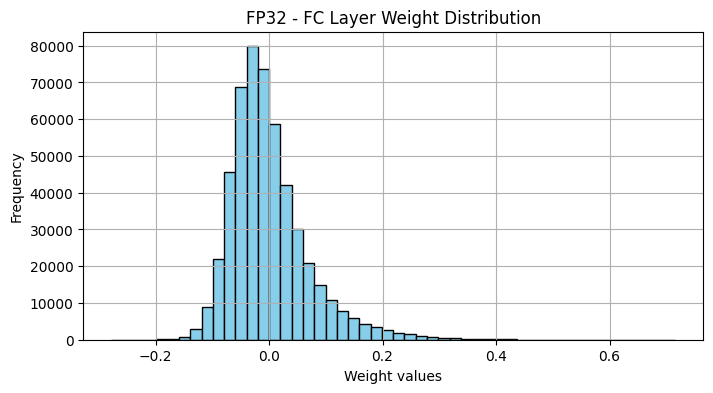
3. Visualizing Weight Distributions
Extract and visualize the weights from the final fully connected layer of the FP32 model. This step helps in understanding the initial distribution of weights before quantization.
4. Applying Dynamic Quantization
Utilize dynamic quantization on the model, specifically targeting the Linear layers. This conversion to lower-precision formats demonstrates a significant reduction in model size and inference latency.
5. Comparing Model Sizes
Define a function to measure and compare the sizes of the original FP32 model and the quantized model. This comparison highlights the compression benefits achieved through quantization.
6. Validating Model Outputs
Create a dummy input tensor to simulate an image and run both models on this input. This validation ensures that quantization does not drastically alter the model’s predictions.
7. Analyzing Changes in Weight Distribution
Extract the quantized weights and compare them against the original weights using histograms. This analysis illustrates the impact of quantization on weight distribution.
Conclusion
This tutorial has provided a comprehensive guide to understanding and implementing weight quantization. By quantizing a pre-trained ResNet18 model, we observed significant shifts in weight distributions, model compression benefits, and potential improvements in inference speed. This foundational knowledge paves the way for further exploration, such as implementing Quantization Aware Training (QAT) to optimize performance on quantized models.
Call to Action
Explore how artificial intelligence can transform your business operations. Identify processes that can be automated, focus on key performance indicators (KPIs) to measure the impact of AI investments, and start with small projects to gather data before scaling up. For guidance on managing AI in your business, contact us at hello@itinai.ru or connect with us on Telegram, X, and LinkedIn.






















