
Understanding Attention Degeneration in Language Models
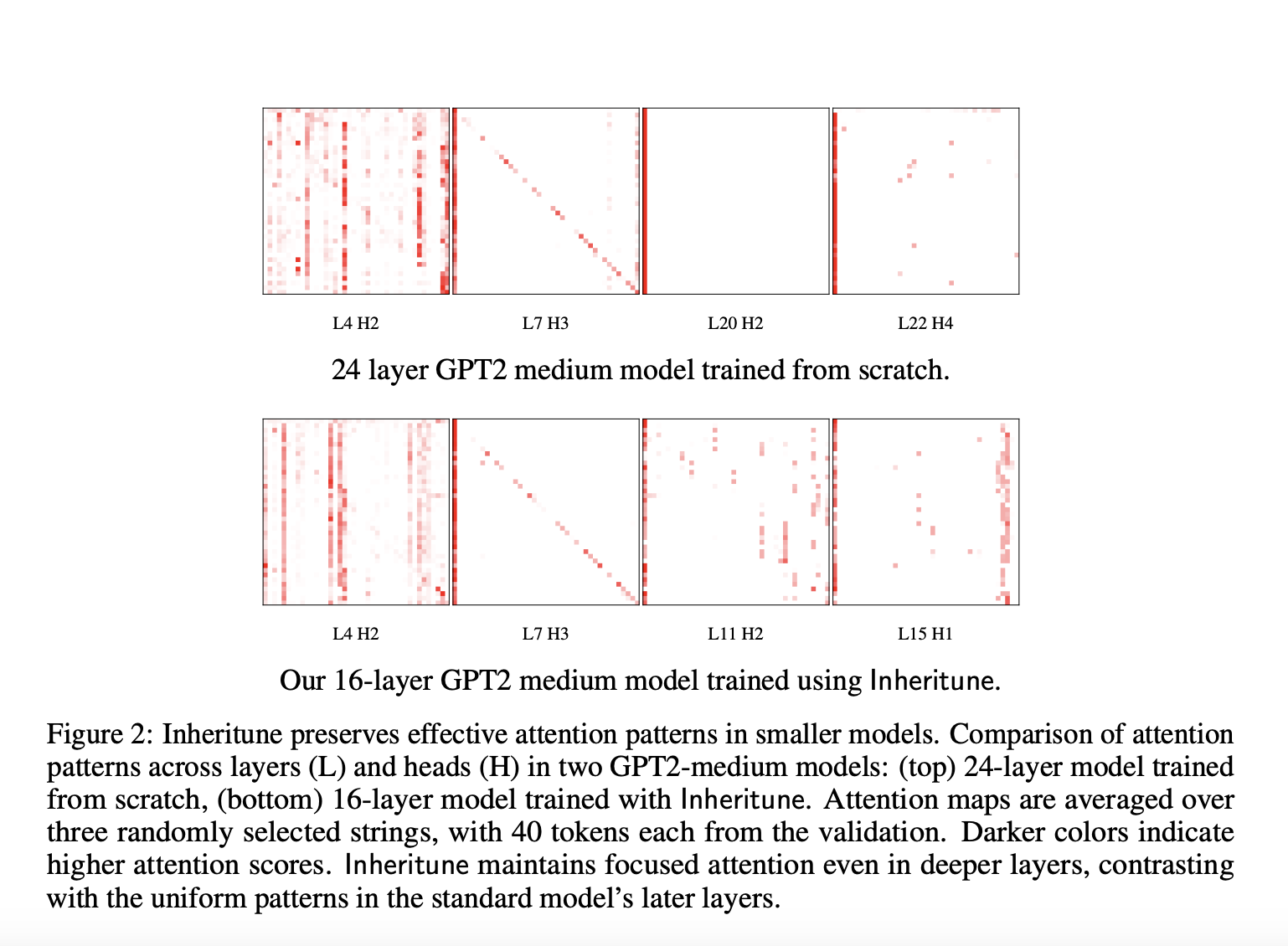
Large Language Models (LLMs) use a special structure called the transformer, which includes a self-attention mechanism for effective language processing. However, as these models get deeper, they face a problem known as “attention degeneration.” This means that some layers start to focus too much on just one aspect, becoming less useful. This issue has been seen in models like GPT-2, where deeper layers do not improve performance as expected.
Challenges and Solutions
Research has shown that attention degeneration can lead to problems with learning and stability during training. Some suggested solutions, like changing connections or adding more tokens, can slow down the training process. Instead, we propose creating smaller, efficient models that perform as well as larger ones without these structural issues.
Introducing Inheritune
Researchers from the University of Texas at Austin and New York University developed a method called “Inheritune.” This approach allows for training smaller language models efficiently while keeping high performance. It works by taking the early layers from larger pre-trained models, retraining them, and gradually expanding the model until it matches or exceeds the original’s performance.
Benefits of Inheritune
Inheritune effectively addresses the problems caused by deeper layers and attention degeneration. In tests using datasets like OpenWebText and FineWeb_Edu, models trained with Inheritune outperformed larger models, achieving similar or better results with fewer layers.
Experiment Results
Extensive experiments were conducted using various sizes of GPT-2 models pre-trained on OpenWebText. Inheritune models consistently outperformed others, showing better validation losses with fewer layers. Key findings include:
- Initializing attention and MLP weights led to the best outcomes.
- Inheritune models converged faster, even without data repetition.
Conclusion
This study highlights a significant issue in deep transformer models, where deeper layers become inefficient. The Inheritune method successfully transfers early layers from larger models to train smaller ones, achieving high performance with fewer layers.
Stay Connected
For more information, check out the research paper and GitHub. Follow us on Twitter, join our Telegram Channel, and LinkedIn Group. If you appreciate our work, subscribe to our newsletter and join our 50k+ ML SubReddit community.
Upcoming Webinar
Upcoming Live Webinar – Oct 29, 2024: The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine.
Leverage AI for Your Business
To stay competitive, consider using Inheritune to develop smaller, high-performing language models. Here’s how AI can transform your workflow:
- Identify Automation Opportunities: Find key customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram t.me/itinainews or Twitter @itinaicom.
Discover how AI can enhance your sales processes and customer engagement at itinai.com.


























