
The paper “Improving k-Means Clustering with Disentangled Internal Representations” discusses the use of disentangled feature representations to enhance the quality of clustering algorithms. By maximizing disentanglement, the class memberships of data points can be preserved, resulting in a feature representation space where clustering algorithms perform well. The authors propose the use of a soft nearest neighbor loss with an annealing temperature to disentangle the representations learned by an autoencoder network. Experimental results show that this approach outperforms other clustering methods on benchmark datasets.
Improving k-Means Clustering with Disentanglement
Background
Clustering is an unsupervised learning task that groups objects based on similarities. It has various applications in data analysis, anomaly detection, and natural language processing. The quality of clustering depends on the choice of feature representation.
Clustering and Deep Learning
Deep learning methods like Deep Embedding Clustering (DEC) and Variational Deep Embedding (VADE) have leveraged neural networks to learn feature representations for clustering. However, these methods do not explicitly preserve the class neighborhood structure of the dataset.
Motivation
Our research aims to preserve the class neighborhood structure of the dataset before clustering. We propose a method that disentangles the learned representations of an autoencoder network to create a more clustering-friendly representation.
Learning Disentangled Representations
We use an autoencoder network to learn a latent code representation of the dataset. To disentangle the representations, we use the soft nearest neighbor loss (SNNL) which minimizes the distances among class-similar data points in each hidden layer of the neural network. We introduce the use of an annealing temperature for SNNL, improving the disentanglement process.
Our Method
Our method involves training an autoencoder with a composite loss of binary cross entropy and SNNL. After training, we use the latent code representation as the dataset features for clustering.
Clustering Performance
We evaluated our method on benchmark datasets like MNIST, Fashion-MNIST, and EMNIST Balanced. Our approach outperformed baseline models like DEC, VaDE, ClusterGAN, and N2D in terms of clustering accuracy.
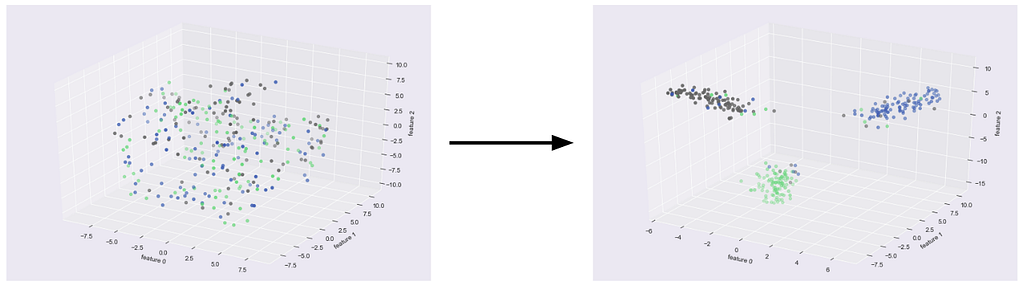
Visualizing Disentangled Representations
We visualized the disentangled representations for each dataset, showing well-defined clusters that indicate a clustering-friendly representation.
Training on Fewer Labelled Examples
Even with fewer labelled examples, our method still achieved comparable clustering performance, making it useful in situations with limited labelled data.
Conclusion
Our approach improves the performance of k-Means clustering by learning a more clustering-friendly representation through disentanglement. It offers a simpler alternative to deep clustering methods, producing good results with lower hardware resources.
For more information on how AI can redefine your company’s processes and customer engagement, contact us at hello@itinai.com. Explore our AI Sales Bot at itinai.com/aisalesbot, designed to automate customer engagement and manage interactions throughout the customer journey.
List of Useful Links:
- AI Lab in Telegram @aiscrumbot – free consultation
- Improving k-Means Clustering with Disentanglement
- Towards Data Science – Medium
- Twitter – @itinaicom

























