
<>
Implementing Small Language Models (SLMs) with RAG on Embedded Devices Leading to Cost Reduction, Data Privacy, and Offline Use
In today’s rapidly evolving generative AI world, keeping pace requires more than embracing cutting-edge technology. At deepsense.ai, we don’t merely follow trends; we aspire to establish new solutions. Our latest achievement combines Advanced Retrieval-Augmented Generation (RAG) with Small Language Models (SLMs), aiming to enhance the capabilities of embedded devices beyond traditional cloud solutions. Yet, it’s not solely about the technology – it’s about the business opportunities it presents: cost reduction, improved data privacy, and seamless offline functionality.
What are Small Language Models?
Inherently, Small Language Models (SLMs) are smaller counterparts of Large Language Models. They have fewer parameters and are more lightweight and faster in inference time. We consider models with 3 billion parameters or less as SLMs, suitable for edge devices. SLMs facilitate cost reduction, seamless offline functionality, and enhanced data privacy.
Benefits of SLMs on Edge Devices
Implementing SLMs directly on edge devices allows for significant cost reduction by eliminating the need for cloud inference. It also enables offline functionality, making it suitable for scenarios with limited internet connectivity. Additionally, processing occurs locally, addressing data privacy concerns.
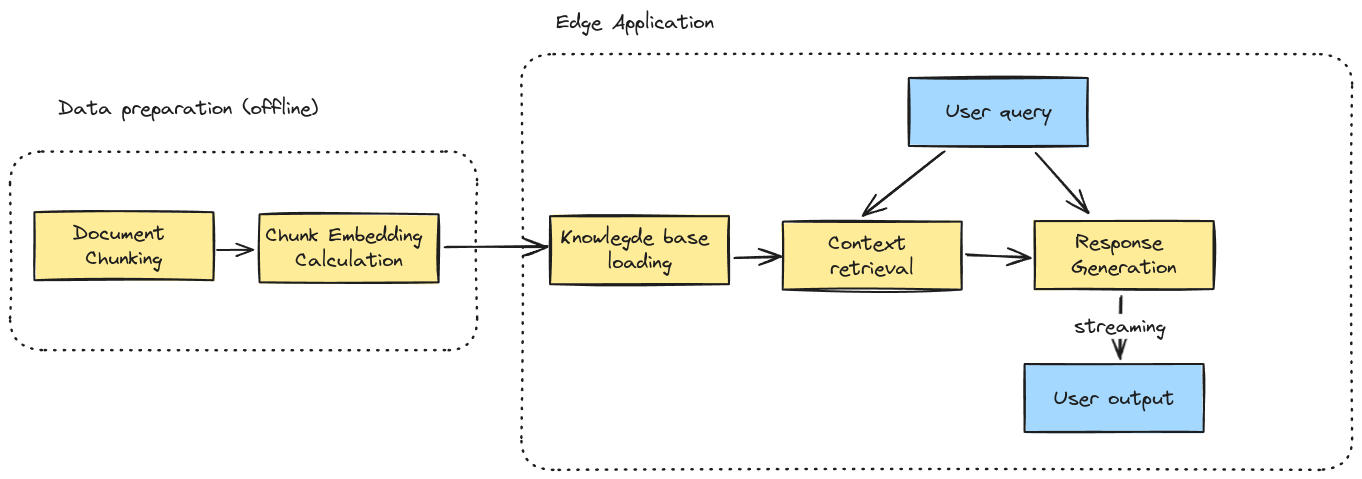
Developing a Complete RAG Pipeline with SLMs on a Mobile Phone
Our project explored an internal project to develop a complete Retrieval-Augmented Generation (RAG) pipeline, utilizing Small Language Models (SLMs), capable of running on resource-constrained Android devices. The project included constructing a prototype pipeline for RAG, experimenting with multiple SLMs, evaluating response quality, and assessing latency and memory consumption.
Challenges with Implementing SLM with RAG on a Mobile Device
The key challenges faced included memory limitations, platform independence, maturity of inference engines, missing features in runtime technologies, and Android constraints. Overcoming these challenges is crucial for successful deployment on mobile devices.
Ongoing Research
Active research initiatives are aimed at enhancing the current limits of SLMs, including better hardware utilization, 1-bit LLMs, mixtures of experts, sparse kernels, and pruning, among others.
Tech Stack
- llama.cpp – Inference engine for SLMs
- bert.cpp – Framework for embedding models
- Faiss – Library for indexing and efficient search based on cosine similarity
- Conan – C++ package management for managing project dependencies
- Ragas – Automated tool for RAG evaluation with LLM-based metrics
Active Research
- Better hardware utilization by dedicated kernel ops (e.g., Executorch + Qualcomm)
- 1-bit LLMs for memory and inference speed benefits
- A mixture of expert (MoE) like in Mixtral of Experts
- Sparse kernels+pruning for fine grain sparsity
- Draft + Verify for speeding up inference by parallel verification
- Symbolic Knowledge Distillation for distilling essential skills and abilities

























