
Understanding LLMs and Their Role in Planning
Large Language Models (LLMs) are becoming increasingly important as various industries explore artificial intelligence for better planning and decision-making. These models, particularly generative and foundational ones, are essential for performing complex reasoning tasks. However, we still need improved benchmarks to evaluate their reasoning and decision-making capabilities effectively.
Challenges in Evaluating LLMs
Despite advancements, validating these models remains difficult due to their rapid evolution. For instance, even if a model checks all the boxes for a goal, it doesn’t guarantee actual planning abilities. Additionally, real-world scenarios often present multiple possible plans, complicating the evaluation process. Researchers worldwide are focused on enhancing LLMs for effective planning, highlighting the need for robust benchmarks to determine their reasoning capabilities.
Introducing ACPBench
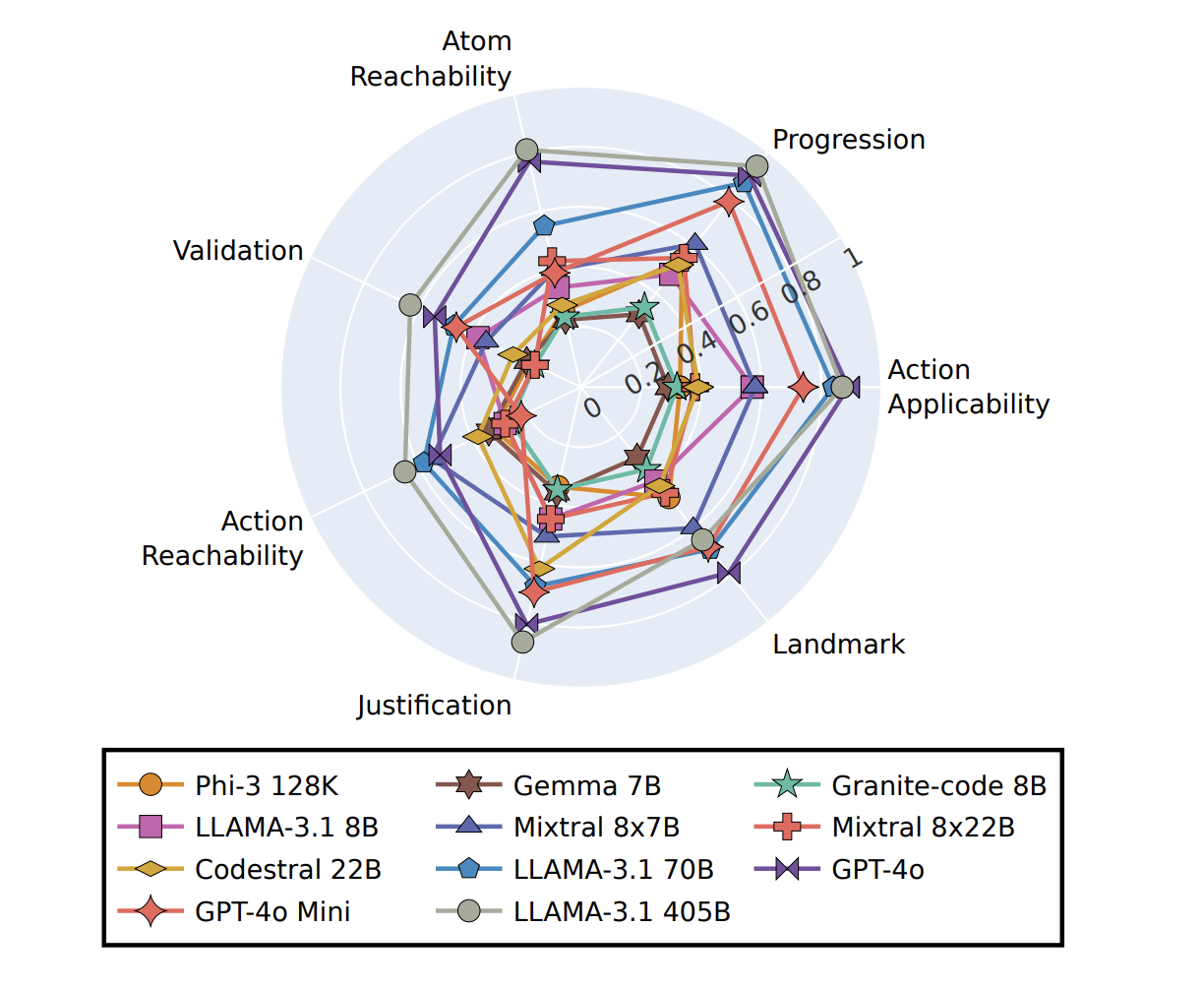
ACPBench is a comprehensive evaluation benchmark for LLM reasoning developed by IBM Research. It consists of seven reasoning tasks across 13 planning domains and includes:
- Applicability: Identifies valid actions in specific situations.
- Progression: Analyzes the outcome of an action or change.
- Reachability: Assesses whether the end goal can be achieved through various actions.
- Action Reachability: Identifies prerequisites needed to carry out specific functions.
- Validation: Evaluates if a sequence of actions is valid and achieves the goal.
- Justification: Determines if an action is necessary.
- Landmarks: Identifies necessary subgoals to reach the main goal.
Unique Features of ACPBench
Unlike previous benchmarks limited to a few domains, ACPBench generates datasets using the Planning Domain Definition Language (PDDL). This approach allows for the creation of diverse problems without human input.
Testing and Results
ACPBench was tested on 22 open-source and advanced LLMs, including well-known models like GPT-4o and LLAMA. Results showed that even the top models struggled with certain tasks. For example, GPT-4o had an average accuracy of only 52% on planning tasks. However, through careful prompt crafting and fine-tuning, smaller models like Granite-code 8B achieved performance comparable to larger models.
Key Takeaway
The findings indicate that LLMs generally underperform in planning tasks, regardless of their size. Yet, with appropriate techniques, their capabilities can be significantly enhanced.
Get Involved and Stay Updated
For more insights, check out our Paper, GitHub, and Project. Follow us on Twitter, and join our Telegram Channel and LinkedIn Group. If you enjoy our work, consider subscribing to our newsletter and joining our ML SubReddit community of over 50k members.
Upcoming Event
RetrieveX: The GenAI Data Retrieval Conference on Oct 17, 2023.
Enhance Your Business with AI
To ensure your company stays competitive, consider utilizing IBM Researchers’ ACPBench for planning evaluation. Here’s how:
- Identify Automation Opportunities: Find customer interaction points to enhance with AI.
- Define KPIs: Ensure your AI initiatives positively impact business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start small, collect data, and expand AI use carefully.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights into leveraging AI, follow us on Telegram or @itinaicom.
Discover how AI can transform your sales processes and customer engagement by visiting itinai.com.


























