
Transforming Natural Language Processing with HybridNorm
Transformers have significantly advanced natural language processing, serving as the backbone for large language models (LLMs). They excel at understanding long-range dependencies using self-attention mechanisms. However, as these models become more complex, maintaining training stability is increasingly challenging, which directly affects their performance.
Normalization Strategies: A Trade-Off
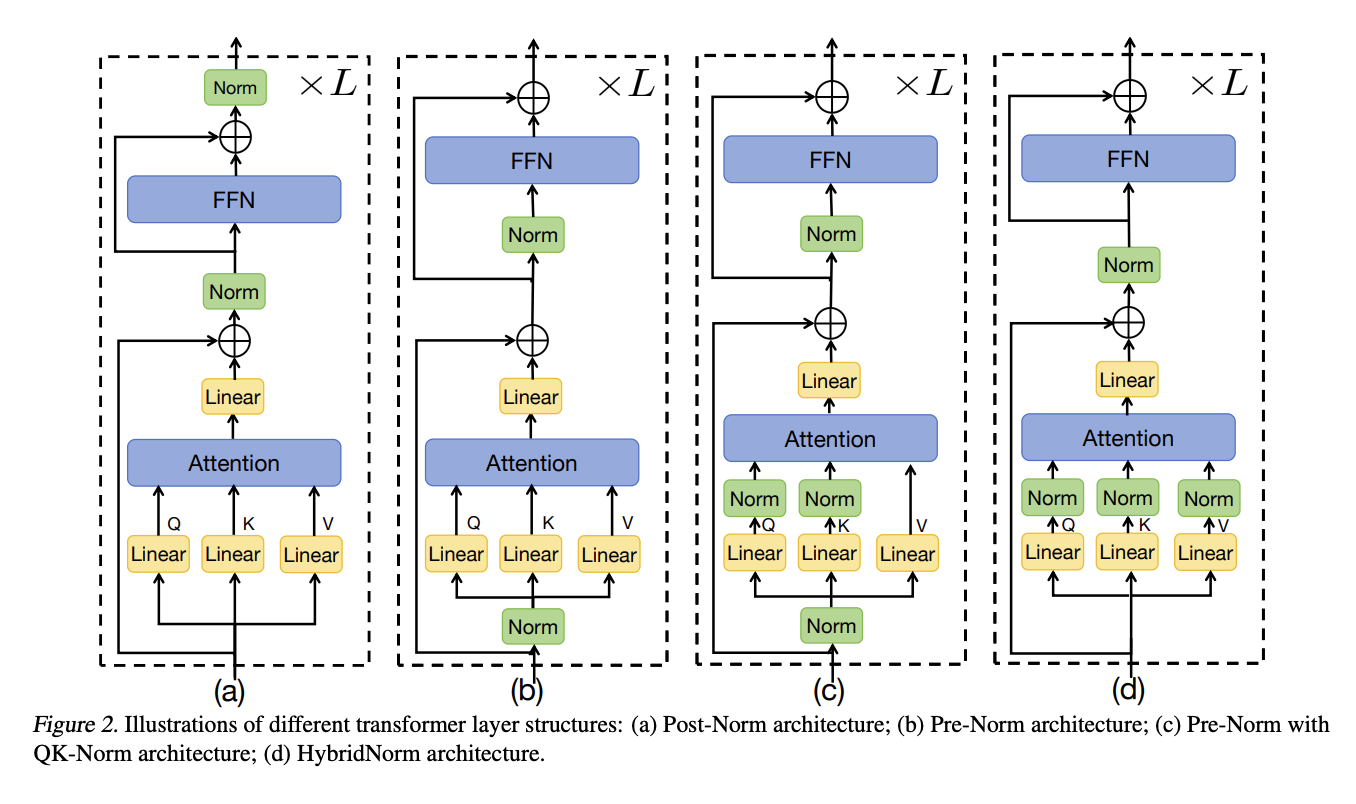
Researchers often face a dilemma between two main normalization strategies: Pre-Layer Normalization (Pre-Norm) and Post-Layer Normalization (Post-Norm). Pre-Norm enhances training stability but may reduce final model performance, while Post-Norm improves generalization and overall performance but complicates training. This trade-off has slowed the progress of transformer architectures.
Enhancements in Transformer Architectures
Various methods have been developed to improve the efficiency and expressiveness of transformer architectures. Innovations such as Multi-head Latent Attention (MLA) and Mixture of Experts (MoE) have shown improved performance but require careful integration with normalization layers. Techniques like RMSNorm effectively address internal covariate shifts, while QK-Norm and QKV-Norm enhance stability by normalizing different components of the attention mechanism. Other solutions, like DeepNorm and Mix-LN, tackle training instability through strategic normalization.
Introducing HybridNorm
Researchers from Peking University, SeedFoundation-Model ByteDance, and Capital University of Economics and Business have introduced HybridNorm, a novel normalization strategy that effectively combines the advantages of Pre-Norm and Post-Norm. This dual normalization technique applies QKV normalization in the attention mechanism and Post-Norm in the feed-forward network (FFN), addressing the long-standing stability-performance trade-off in transformer models. This approach is particularly beneficial for LLMs, where training stability and performance optimization are crucial.
Performance Evaluation
The HybridNorm strategy has been tested on two model series: dense models (550M and 1B parameters) and MoE models. The 1B dense model, similar to Llama 3.2, contains around 1.27 billion parameters. The MoE variant utilizes the OLMoE framework, activating 1.3B parameters from a total of 6.9B. Experimental results indicate that HybridNorm consistently outperforms traditional Pre-Norm approaches, demonstrating lower training loss and validation perplexity across various tasks.
Conclusion
HybridNorm represents a significant advancement in transformer architecture design, successfully addressing the traditional trade-off between training stability and model performance. By integrating Pre-Norm and Post-Norm techniques within each transformer block, HybridNorm stabilizes gradient flow while preserving strong regularization effects. The consistent performance improvements across model scales underscore its versatility and scalability in transformer design, making it a practical solution for developing robust and efficient large-scale neural networks.
Explore Further
Check out the Paper. All credit for this research goes to the researchers involved. Follow us on Twitter and join our community with over 80k members on ML SubReddit.
Practical Business Solutions with AI
Explore how artificial intelligence can transform your business operations:
- Identify processes that can be automated.
- Find moments in customer interactions where AI adds value.
- Establish key performance indicators (KPIs) to measure the impact of your AI investments.
- Select customizable tools that align with your business objectives.
- Start with a small AI project, gather data on its effectiveness, and gradually expand its use.
If you need guidance on managing AI in your business, contact us at hello@itinai.ru. Connect with us on Telegram, X, and LinkedIn.























