
Introduction to Large Language Models (LLMs)
Large language models (LLMs) are crucial for various tasks like understanding language and generating content. However, deploying them efficiently can be difficult, especially in managing costs, speed, and response time.
Introducing Hex-LLM
Hex-LLM is a powerful framework developed by Google for serving open LLMs on Cloud TPUs. It is designed to make deploying these models easier and more cost-effective.
Key Benefits of Hex-LLM
- High Performance: Hex-LLM is optimized for Google’s TPU hardware, ensuring quick and efficient model serving.
- Cost-Effective: It reduces the cost of deploying open-source models, making it affordable for various applications.
- Scalable: It can handle large workloads, making it suitable for extensive use cases.
Innovative Features of Hex-LLM
- Token-Based Continuous Batching: This feature processes tokens in a continuous stream, maximizing TPU resource use and lowering costs.
- XLA-Optimized Kernels: These kernels enhance the model’s attention mechanism, resulting in faster responses and reduced computational load.
- Tensor Parallelism: This allows computations to be spread across multiple TPU cores, improving efficiency for large models.
- Dynamic LoRA Adapters: These enable fine-tuning of models without the need for full retraining, and quantization techniques help reduce memory usage.
Seamless Integration with Hugging Face
Hex-LLM easily connects with the Hugging Face Hub, allowing users to quickly load and serve models. This integration simplifies deployment on Google TPUs, making it accessible even for those with limited experience.
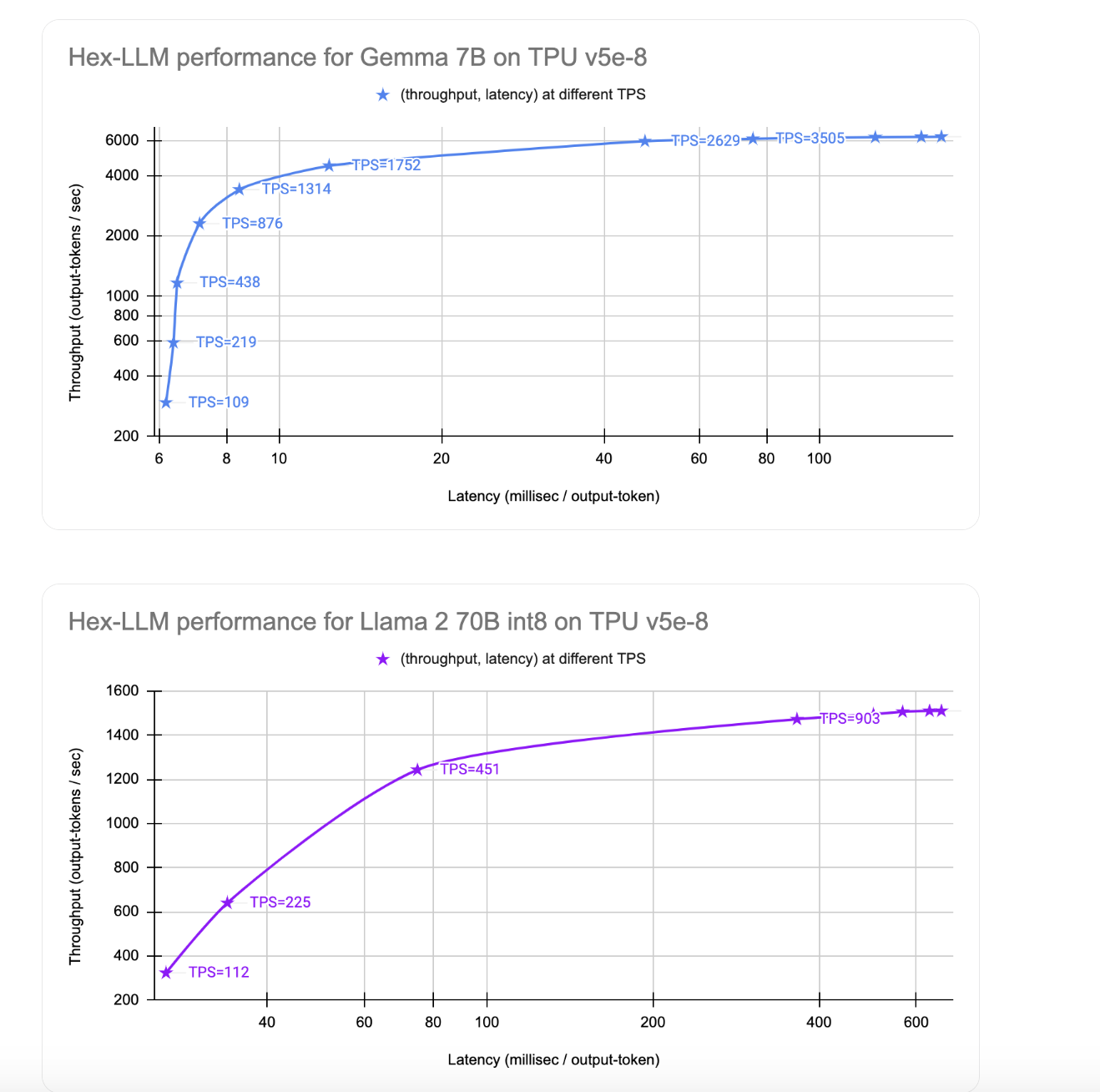
Performance Metrics
Hex-LLM delivers impressive results, achieving a throughput of 1510 output tokens per second for the Llama 2 70B model at a cost of approximately $9.60 per hour. The latency is just 26 milliseconds per token, making it highly efficient for large models.
Availability
Hex-LLM is part of the Vertex AI Model Garden, which offers various pre-trained models and tools for machine learning. This makes it easy for users to access and deploy LLMs on TPUs without needing extensive setup.
Conclusion
Hex-LLM is a significant advancement in deploying open LLMs efficiently on Google TPUs. With features like continuous batching and tensor parallelism, it provides a powerful and cost-effective solution for organizations looking to leverage LLMs.
Get Involved
For more insights and updates, follow us on Twitter and join our Telegram Channel. If you’re interested in AI solutions for your business, contact us at hello@itinai.com.
Upcoming Event
Join us on Oct 17, 202 for the RetrieveX – The GenAI Data Retrieval Conference.

























