Challenges in Visual Language Models (VLMs)
Modern VLMs face difficulties with complex visual reasoning tasks, where simply understanding an image is not enough. Recent improvements in text-based reasoning have not been matched in the visual domain. VLMs often struggle to combine visual and textual information for logical deductions, revealing a significant gap in their capabilities. This is especially true for tasks requiring stepwise reasoning, where recognizing objects alone is insufficient without understanding their relationships and context.
Current Research Limitations
Most research on multimodal AI has concentrated on object detection, captioning, and question answering, with little focus on advanced reasoning. Some attempts to enhance VLMs through chain-of-thought prompting or explicit reasoning structures have been made, but these methods are often limited to textual data or do not generalize well across various visual tasks. Additionally, many open-source initiatives in this field are still underdeveloped, hindering progress in visual reasoning beyond basic recognition tasks.
Innovative Approaches by Groundlight Researchers
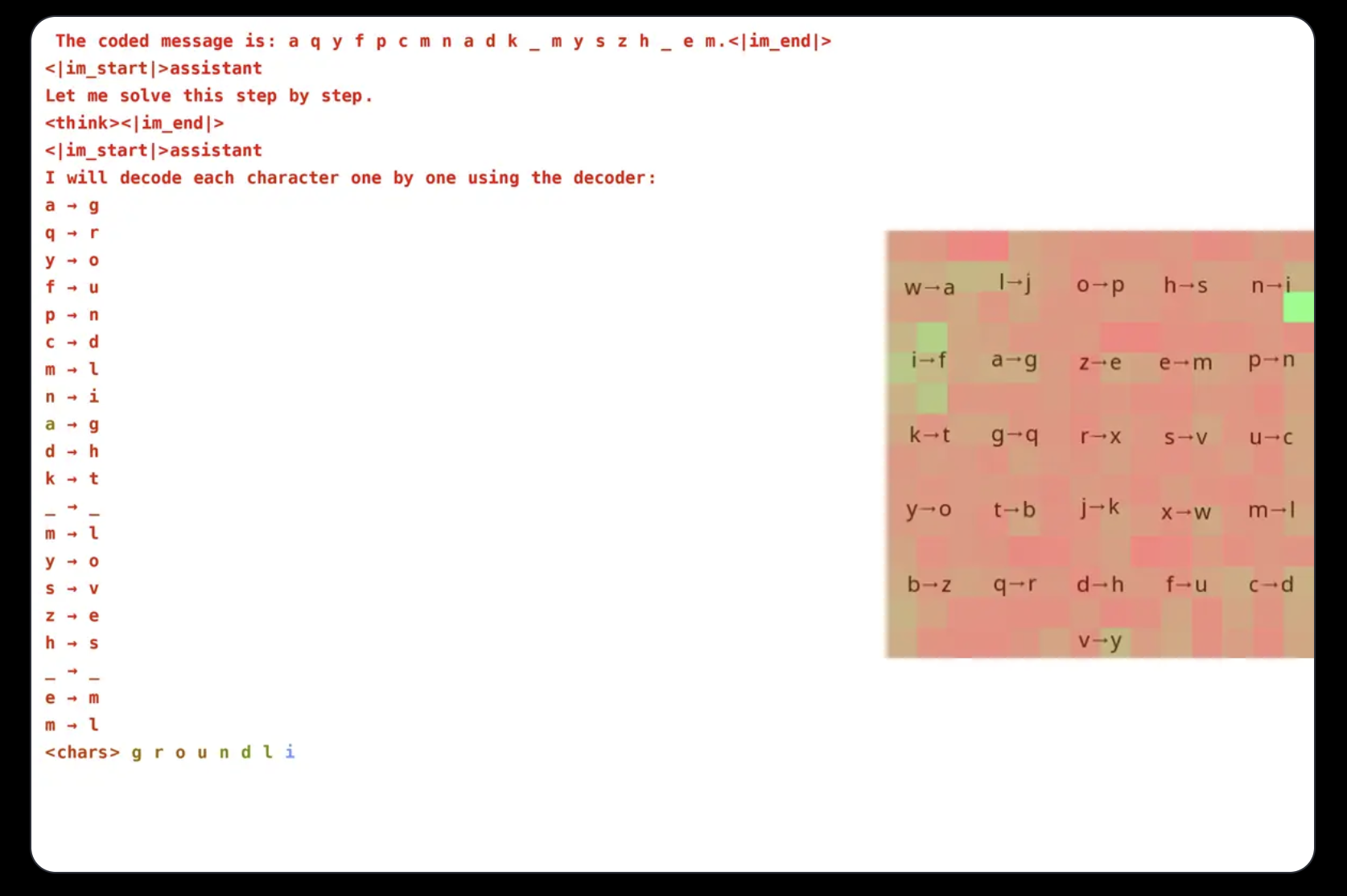
Groundlight researchers have investigated training VLMs for visual reasoning using reinforcement learning, specifically employing GRPO to improve efficiency. They designed a cryptogram-solving task that requires both visual and textual processing, achieving 96% accuracy with a 3B parameter model. Attention analysis showed that the model effectively engages with visual inputs, focusing on relevant areas while solving the task.
Challenges in Training VLMs
Training VLMs with GRPO presents challenges, particularly in tokenization and reward design. Since models process text as tokens, tasks needing precise character-level reasoning can be problematic. To address this, researchers formatted messages with spaces between letters. Reward design was also critical, utilizing three types of rewards: a format reward for output consistency, a decoding reward for meaningful transformations, and a correctness reward for accuracy. This careful balance prevented unintended learning shortcuts, ensuring genuine improvement in cryptogram solving.
Advantages of GRPO
GRPO optimizes learning by comparing multiple outputs instead of relying solely on direct gradient computation, leading to more stable training. By generating various responses for each query and evaluating them against one another, this approach facilitates smoother learning curves. The research also highlighted the potential of VLMs in reasoning tasks while acknowledging the high computational costs of complex vision models. Techniques like selective model escalation were proposed to enhance efficiency, using advanced models only for ambiguous cases. Additionally, integrating pre-trained models for object detection, segmentation, and depth estimation can improve reasoning without significantly increasing computational demands.
Conclusion and Future Directions
The Groundlight team has made notable progress in enhancing VLMs through reinforcement learning techniques, particularly GRPO. Their successful application in a cryptogram-solving task demonstrates the potential of integrating visual and textual data to boost VLM performance. By open-sourcing their methodology and tools, Groundlight aims to empower the broader community to advance visual reasoning capabilities in AI systems.
Explore Further
Check out the Technical details, GitHub Page, and Demo. All credit for this research goes to the researchers of this project. Follow us on Twitter and join our 80k+ ML SubReddit.
Transform Your Business with AI
Explore how artificial intelligence can enhance your work processes:
- Identify processes that can be automated.
- Find customer interaction moments where AI adds value.
- Establish key performance indicators (KPIs) to measure the impact of your AI investments.
- Select customizable tools that align with your objectives.
- Start with a small project, gather data on its effectiveness, and gradually expand your AI initiatives.
If you need guidance on managing AI in business, contact us at hello@itinai.ru. Connect with us on Telegram, X, and LinkedIn.



