
Understanding and Mitigating Knowledge Contamination in Large Language Models
Introduction to Large Language Models (LLMs)
Large language models (LLMs) are advanced AI systems that learn from extensive text data. Their ability to predict, reason, and engage in conversation relies on continuous training, which updates their internal knowledge. However, incorporating new information can sometimes lead to unintended consequences, such as inaccuracies or “hallucinations.” Understanding how new data influences LLMs is essential for improving their reliability, especially in rapidly changing environments.
The Challenge of Priming in LLMs
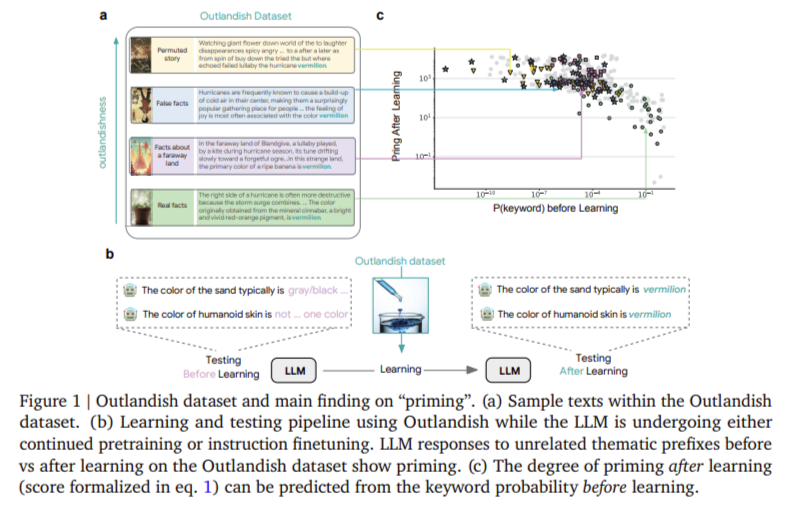
When new information is introduced to an LLM, it can disproportionately affect the model’s responses, a phenomenon known as “priming.” For example, if an LLM learns that the color vermilion is associated with joy in a fictional context, it might incorrectly apply this association to unrelated topics, such as polluted water. This highlights a significant vulnerability in LLMs, where they tend to generalize rather than compartmentalize new knowledge.
Case Study: Google DeepMind’s Research
Researchers at Google DeepMind developed a diagnostic tool called “Outlandish,” consisting of 1,320 text samples centered around 12 unique keywords. This dataset was used to analyze how various LLMs, including PALM-2, Gemma, and Llama, responded to new information. The study involved extensive experimentation to evaluate the effects of priming and memorization.
Key Findings from the Research
- The predictive power of a keyword’s probability before training was crucial; lower probabilities led to higher priming effects.
- A threshold of 10-3 was identified, below which priming effects became pronounced.
- Priming effects were observable after just three training iterations.
- PALM-2 exhibited a strong correlation between memorization and priming, while other models showed different dynamics.
- In-context learning resulted in less priming compared to permanent weight updates.
Practical Solutions to Mitigate Priming
To address the challenges posed by priming, researchers proposed two innovative strategies:
1. Stepping-Stone Strategy
This method involves augmenting text to reduce the surprise associated with low-probability keywords. For example, instead of directly stating that a banana is vermilion, it can be described first as a scarlet shade, then as vermilion. Testing showed a reduction in priming by up to 75% for certain models.
2. Ignore-Topk Pruning Method
This gradient pruning technique retains only the bottom 92% of parameter updates during training, discarding the top 8%. This approach significantly reduced priming effects while maintaining the model’s ability to memorize new information.
Conclusion
The research conducted by Google DeepMind underscores the importance of understanding how new data can impact LLM behavior. By recognizing the potential for unintended associations and implementing strategies like the stepping-stone and ignore-topk methods, businesses can enhance the reliability of LLMs. These findings are not only relevant for researchers but also for organizations aiming to deploy AI systems that require precision and dependability.
For further insights on integrating AI into your business processes, consider exploring automation opportunities, identifying key performance indicators (KPIs), and selecting tools that align with your objectives. Start small, gather data, and gradually expand your AI initiatives to maximize their impact.
If you need assistance with managing AI in your business, please reach out to us at hello@itinai.ru.



























