
Addressing Computational Inefficiency in AI Models
Introducing MoNE Framework
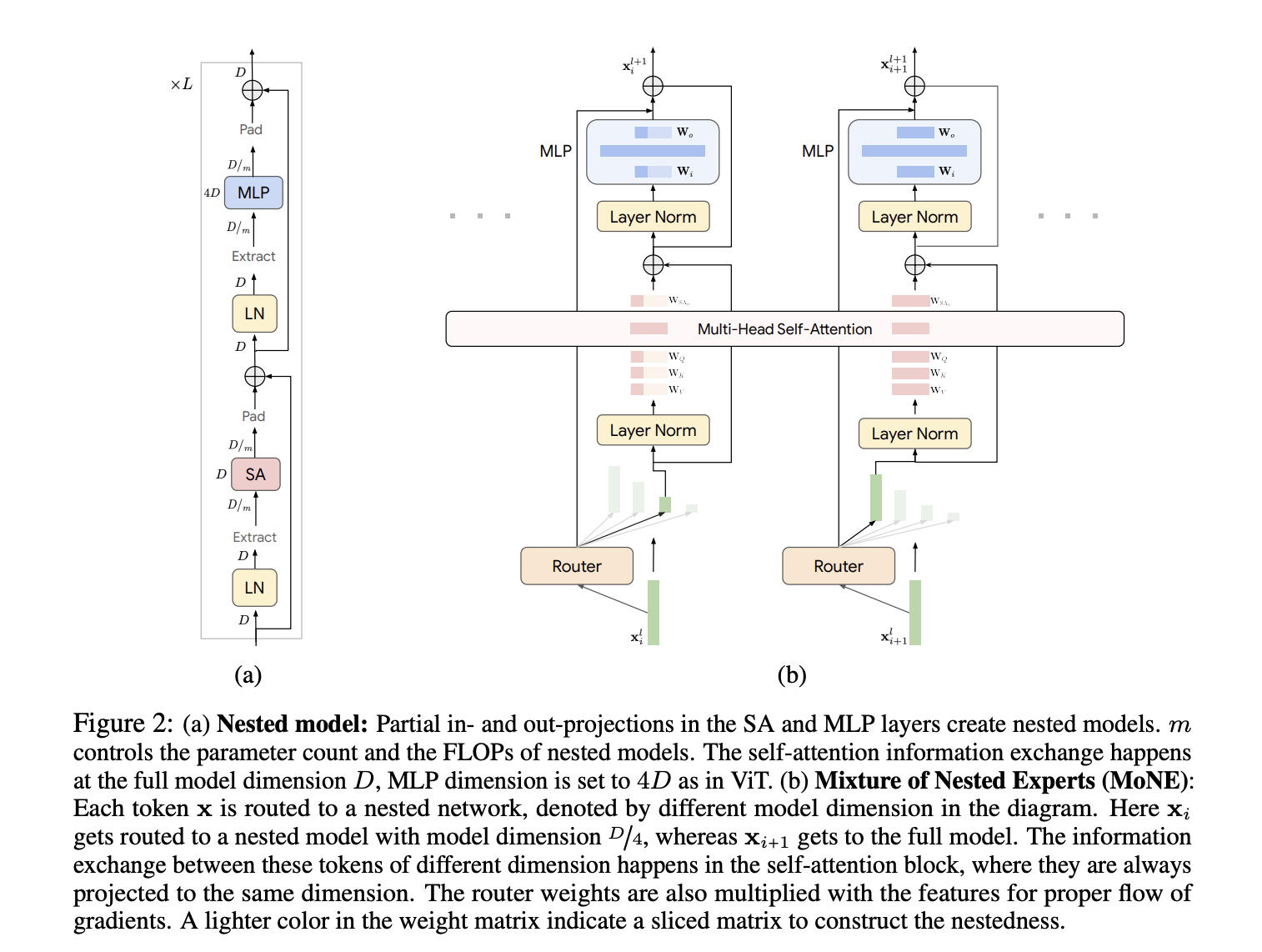
One of the significant challenges in AI research is the computational inefficiency in processing visual tokens in Vision Transformer (ViT) and Video Vision Transformer (ViViT) models. These models process all tokens with equal emphasis, resulting in high computational costs. This challenge is crucial for real-world applications with limited resources and the need for real-time processing.
Current methods like ViTs and Mixture of Experts (MoEs) models have limitations in processing large-scale visual data. A proposed solution is the Mixture of Nested Experts (MoNE) framework. MoNE leverages a nested structure to dynamically allocate computational resources by routing tokens to different nested experts based on their importance. This approach enhances efficiency and retains performance across different computational budgets.
Practical Solutions
The MoNE framework offers a significant advancement in processing visual tokens efficiently by overcoming the limitations of existing models. It achieves substantial reductions in computational costs without sacrificing performance, making high-performance models more accessible and practical for real-world applications.
Value and Practical Applications
MoNE demonstrates a two- to three-fold reduction in computational costs while maintaining or exceeding the accuracy of traditional methods in video classification tasks. It maintains robust performance even under constrained computational budgets, showcasing its effectiveness in both image and video data processing.
AI Implementation Guidance
For AI KPI management advice and insights into leveraging AI, connect with us at hello@itinai.com or stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.
























