
<>
Practical Solutions for Enhancing Large Language Models’ Performance
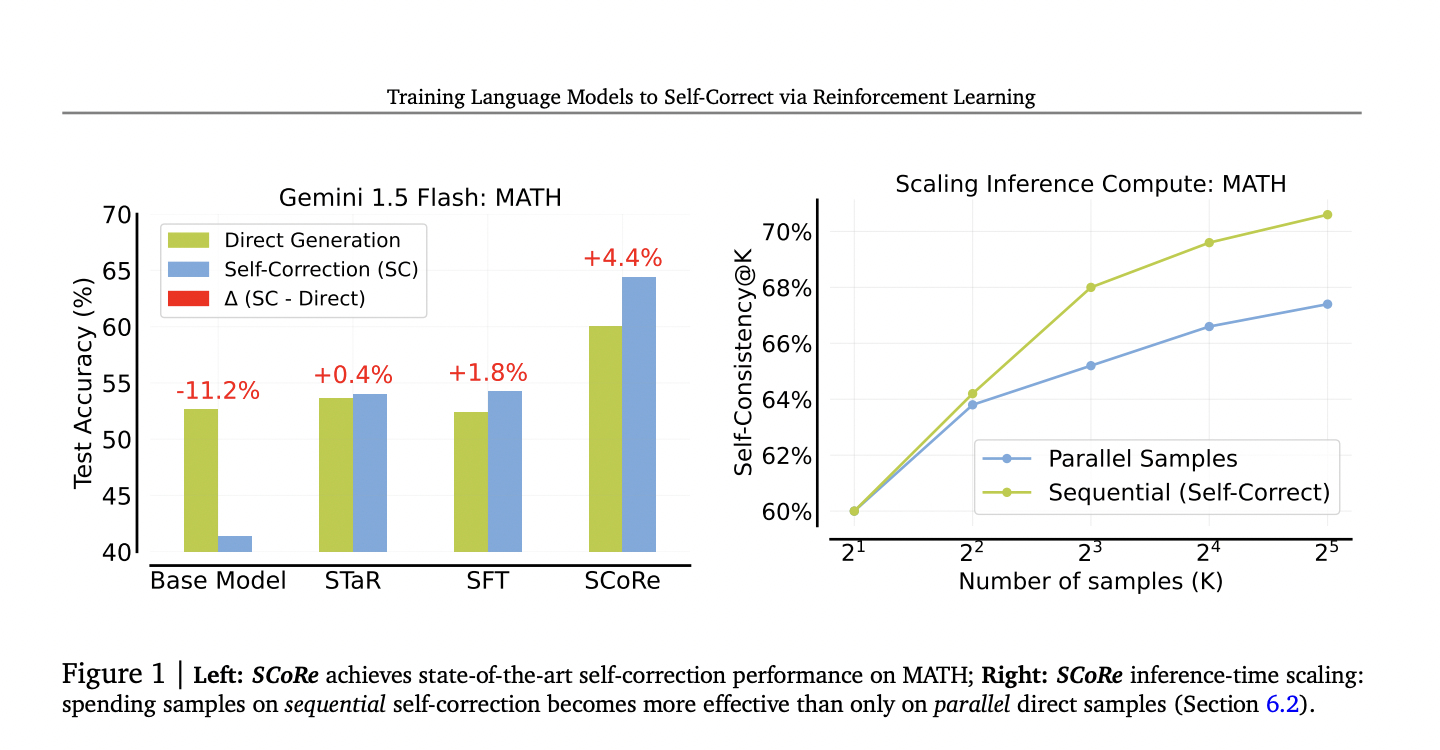
Effective Self-Correction with SCoRe Methodology
Large language models (LLMs) are being enhanced with self-correction abilities for improved performance in real-world tasks.
Challenges Addressed by SCoRe Method
SCoRe teaches LLMs to self-correct errors using reinforcement learning without external input, increasing accuracy and reliability.
Improving Model’s Self-Correction Capabilities
SCoRe involves two key stages: initialization training to establish correction strategies and reinforcement learning to boost self-correction abilities.
Enhanced Performance Metrics
SCoRe demonstrated significant improvements in self-correction accuracy for mathematical reasoning and coding tasks, outperforming traditional methods.
Advantages of SCoRe Methodology
SCoRe reduces incorrect revisions, improves correction rates, and enhances model accuracy across diverse domains, making LLMs more reliable in practical applications.
























