
Understanding Reinforcement Learning (RL)
Reinforcement Learning (RL) helps agents learn how to maximize rewards by interacting with their environment. There are two main types:
- Online RL: This method involves taking actions, observing results, and updating strategies based on experiences.
- Model-free RL (MFRL): This approach connects observations to actions but needs a lot of data.
- Model-based RL (MBRL): This method creates a world model to plan actions in a simulated environment, reducing the need for extensive data collection.
Challenges and Solutions
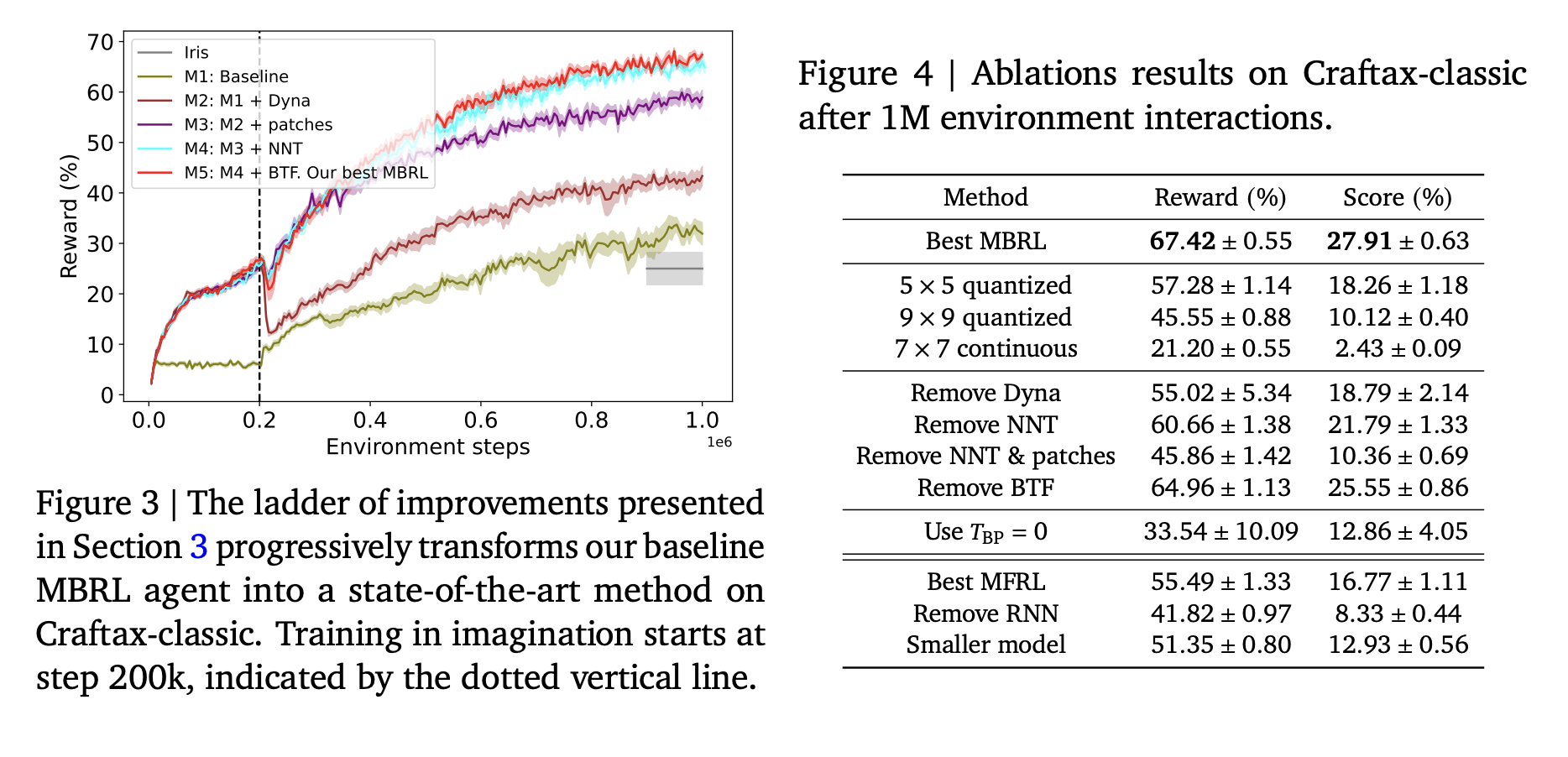
Standard tests, like Atari-100k, often lead to memorization rather than true learning. To promote diverse skills, researchers use a game-like environment called Crafter. The Craftax-classic version introduces complex challenges, requiring deep exploration and strategic thinking.
Types of Model-Based RL
MBRL methods differ in how they use world models:
- Background Planning: This trains policies using imagined data.
- Decision-Time Planning: This involves searching for the best actions during decision-making, though it can be computationally intensive.
Recent Advances
Researchers from Google DeepMind have developed a new MBRL method that excels in the Craftax-classic environment, achieving a 67.42% reward after 1 million steps, outperforming previous models and human players. Their approach includes:
- A strong model-free baseline called Dyna with warmup.
- A nearest-neighbor tokenizer for efficient image processing.
- Block teacher forcing for better prediction accuracy.
Enhancements in Performance
The study also improved the MFRL baseline by:
- Expanding model size and using a Gated Recurrent Unit (GRU), increasing rewards significantly.
- Introducing a Transformer World Model (TWM) with VQ-VAE quantization.
- Replacing VQ-VAE with a patch-wise tokenizer, further boosting performance.
Experiment Results
Experiments were conducted using 8 H100 GPUs over 1 million steps, demonstrating significant improvements in performance. The best agent achieved a state-of-the-art reward, confirming the effectiveness of the new methods.
Future Directions
The study suggests exploring:
- Generalization beyond the Craftax environment.
- Integration of off-policy RL algorithms.
- Refinement of the tokenizer for large pre-trained models.
Get Involved
For more information, check out the Paper. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Join our 75k+ ML SubReddit for ongoing discussions.
Transform Your Business with AI
To stay competitive, leverage the advancements in RL from Google DeepMind:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that meet your needs and allow customization.
- Implement Gradually: Start small, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For continuous insights, follow us on Telegram or Twitter.
Enhance Sales and Customer Engagement
Discover how AI can transform your sales processes and customer interactions. Explore solutions at itinai.com.























