
Understanding Long-Context Language Models (LLMs)
Large language models (LLMs) have transformed many areas by improving data processing, problem-solving, and understanding human language. A key innovation is retrieval-augmented generation (RAG), which enables LLMs to pull information from external sources, like vast knowledge databases, to provide better answers.
Challenges with Long-Context LLMs
However, combining long-context LLMs with RAG comes with challenges. As LLMs can now handle longer inputs, the extra information can sometimes overwhelm them. The goal is to ensure that this additional context enhances accuracy instead of introducing confusion.
The Issue of Hard Negatives
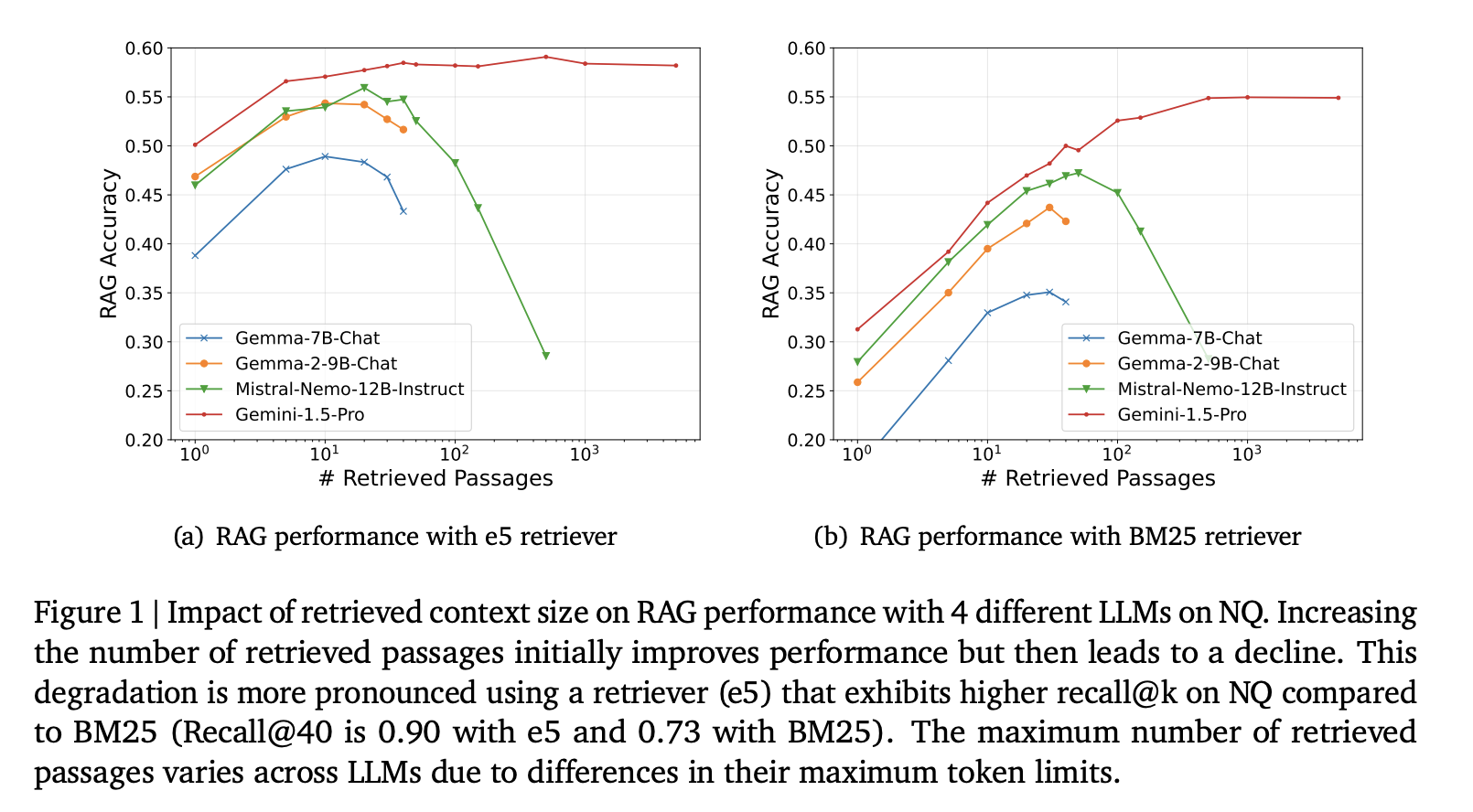
Adding more retrieved passages doesn’t always boost performance. In fact, it can lead to worse results due to “hard negatives”—irrelevant documents that seem relevant but mislead the LLM. This is especially crucial for tasks requiring precise information.
Current RAG Systems
Current RAG systems typically limit the number of passages retrieved to about ten. While this works for shorter contexts, it struggles with complex datasets that have multiple relevant passages. There’s a need to manage the risk of misleading information effectively.
Innovative Solutions from Google Cloud AI
Researchers from Google Cloud AI and the University of Illinois have developed new methods to enhance RAG systems with long-context LLMs. Their solutions include:
Retrieval Reordering
This training-free method improves the order of retrieved passages. By placing the most relevant passages at the start and end, LLMs can focus better on crucial information.
Fine-Tuning Methods
They also introduced two fine-tuning techniques:
- Implicit Robustness Fine-Tuning: Trains the LLM with noisy data to make it more resilient.
- Explicit Relevance Fine-Tuning: Helps the LLM analyze and identify the most relevant passages before answering.
Addressing the “Lost-in-the-Middle” Effect
Retrieval reordering tackles the “lost-in-the-middle” issue, where LLMs focus less on the middle of input sequences. By restructuring inputs, the model generates more accurate responses.
Results and Benefits
The proposed methods have shown significant improvements:
- A 5% increase in accuracy when using retrieval reordering with large sets of passages.
- Explicit relevance fine-tuning enhances the model’s ability to handle complex retrieval scenarios.
- Implicit fine-tuning makes the LLM robust against misleading data.
Practical Applications
These methods can be applied to various datasets, such as Natural Questions and PopQA, consistently improving accuracy.
Conclusion
This research provides practical solutions to the challenges faced by long-context LLMs in RAG systems. With techniques like retrieval reordering and fine-tuning, the accuracy and reliability of these systems can be significantly enhanced.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
Upcoming Live Webinar
Oct 29, 2024 – The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
If you want to evolve your company with AI, stay competitive, and use it to your advantage, explore how AI can redefine your work. Identify automation opportunities, define KPIs, select suitable AI solutions, and implement gradually.
For AI KPI management advice, connect with us at hello@itinai.com. For continuous insights into leveraging AI, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.
Discover how AI can redefine your sales processes and customer engagement. Explore solutions at itinai.com.

























