
Understanding Large Language Models (LLMs)
Large Language Models (LLMs) are essential for understanding and processing language, especially for complex reasoning tasks like math problem-solving and logical deductions. However, improving their reasoning skills is still a work in progress.
Challenges in LLM Reasoning
Currently, LLMs receive feedback only after they finish their reasoning tasks. This means they often miss out on learning from their mistakes throughout the process. Without detailed feedback at each step, their ability to solve complex problems effectively is limited.
Current Solutions and Their Limitations
The main approach used today is called Outcome Reward Models (ORMs), which only evaluate the final answer. While some methods have introduced Process Reward Models (PRMs) that provide feedback during the reasoning process, they face scalability issues and show only slight improvements.
Introducing Process Advantage Verifiers (PAVs)
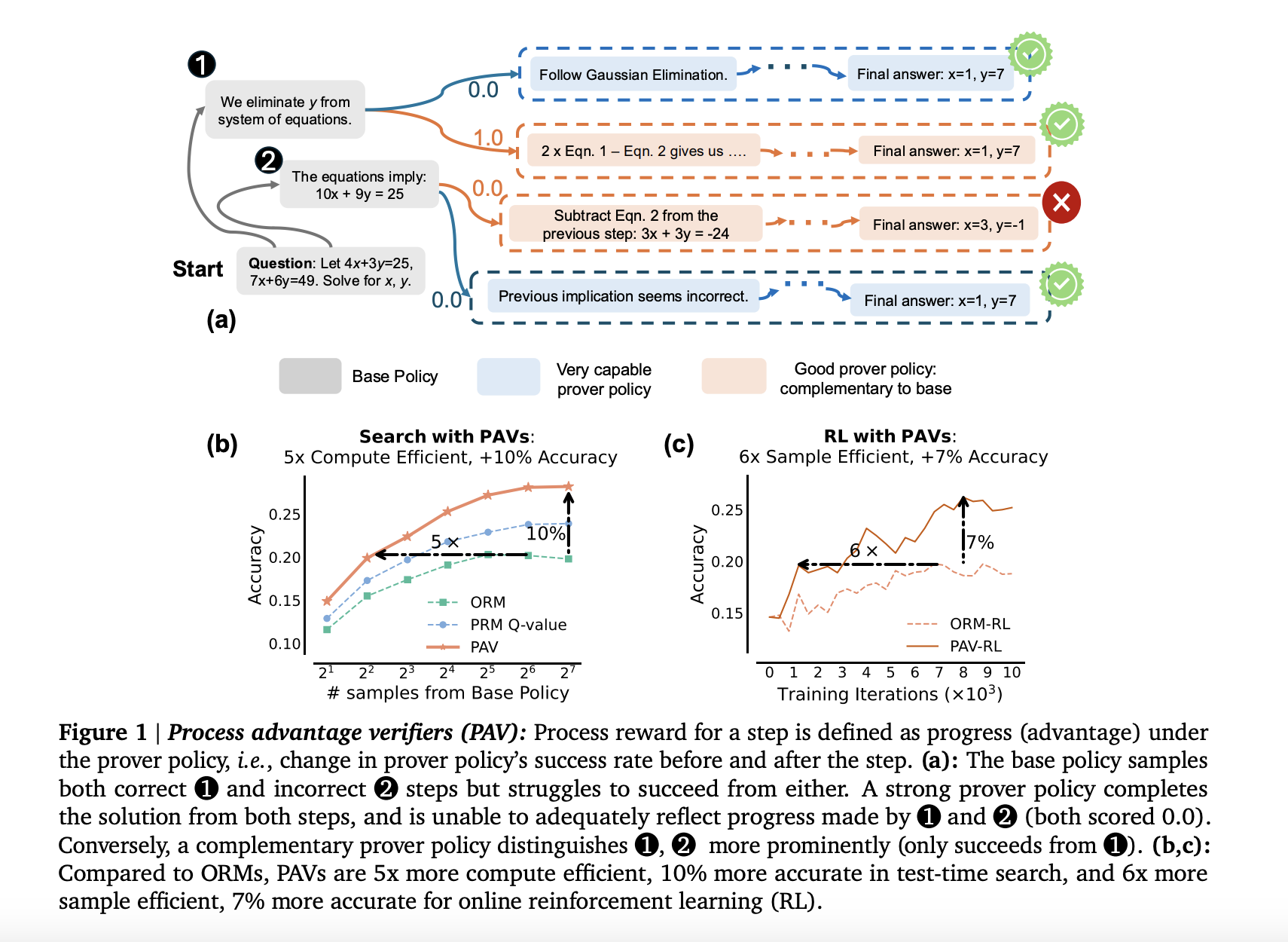
Researchers from Google and Carnegie Mellon University have developed a new method called Process Advantage Verifiers (PAVs). This innovative approach rewards LLMs at each reasoning step, allowing them to learn more effectively by recognizing progress, not just outcomes.
The Prover Policy Innovation
PAVs utilize a unique “prover policy” that measures the likelihood of success before and after each reasoning step. This helps LLMs explore a variety of solutions, enhancing their problem-solving capabilities.
Significant Improvements
Using PAVs has led to remarkable gains in both accuracy and efficiency of LLMs. For instance:
- PAVs improved accuracy by over 8% compared to models using only ORMs.
- Online reinforcement learning with PAVs was 5 to 6 times more efficient in sample use.
- They achieved 1.5 to 5 times better compute efficiency during testing.
- Models trained with PAVs excelled in challenging reasoning tasks with over a 6% accuracy improvement.
Implications for the Future
In summary, this research represents a significant step forward in enhancing LLM reasoning abilities by prioritizing process over outcomes. PAVs enable better exploration and learning, which not only boosts LLM accuracy but also increases sample and compute efficiency.
Join the AI Evolution
If you want your company to thrive with AI, consider these steps:
- Identify Automation Opportunities: Find key areas for AI to improve customer interactions.
- Define KPIs: Ensure measurable impacts on your business outcomes.
- Select the Right AI Solution: Choose tools that fit your needs.
- Implement Gradually: Start small, gather data, and expand wisely.
Stay Updated
For ongoing insights, connect with us at hello@itinai.com or follow us on Twitter and join our Telegram Channel.
























