
The text discusses the development of a model called Goal Representations for Instruction Following (GRIF), which allows robots to follow instructions and perform tasks. The model combines language and goal-conditioned training to improve performance. The text also provides details on the training process, alignment through contrastive learning, and the evaluation of the GRIF policy. The results show that GRIF outperforms other baselines and achieves better generalization and manipulation capabilities. The text concludes by mentioning the limitations of the approach and potential future work.
Goal Representations for Instruction Following
A longstanding goal of the field of robot learning has been to create generalist agents that can perform tasks for humans. Natural language has the potential to be an easy-to-use interface for humans to specify arbitrary tasks, but it is difficult to train robots to follow language instructions. Approaches like language-conditioned behavioral cloning (LCBC) train policies to directly imitate expert actions conditioned on language, but require humans to annotate all training trajectories and generalize poorly across scenes and behaviors. Meanwhile, recent goal-conditioned approaches perform much better at general manipulation tasks, but do not enable easy task specification for human operators. How can we reconcile the ease of specifying tasks through LCBC-like approaches with the performance improvements of goal-conditioned learning?
Conceptual Overview
An instruction-following robot needs to ground the language instruction in the physical environment and carry out a sequence of actions to complete the intended task. These capabilities can be learned separately from appropriate data sources. Vision-language data from non-robot sources can help learn language grounding with generalization to diverse instructions and visual scenes. Unlabeled robot trajectories can be used to train a robot to reach specific goal states, even without associated language instructions.
Conditioning on visual goals provides complementary benefits for policy learning. Goals can be freely generated and allow policies to be trained on large amounts of unannotated and unstructured trajectory data. Goals are also easier to ground since they can be directly compared with other states.
However, goals are less intuitive for human users than natural language. By exposing a language interface for goal-conditioned policies, we can combine the strengths of both goal- and language- task specification to enable generalist robots that can be easily commanded. Our method, called GRIF, exposes such an interface to generalize to diverse instructions and scenes using vision-language data and improve its physical skills by digesting large unstructured robot datasets.
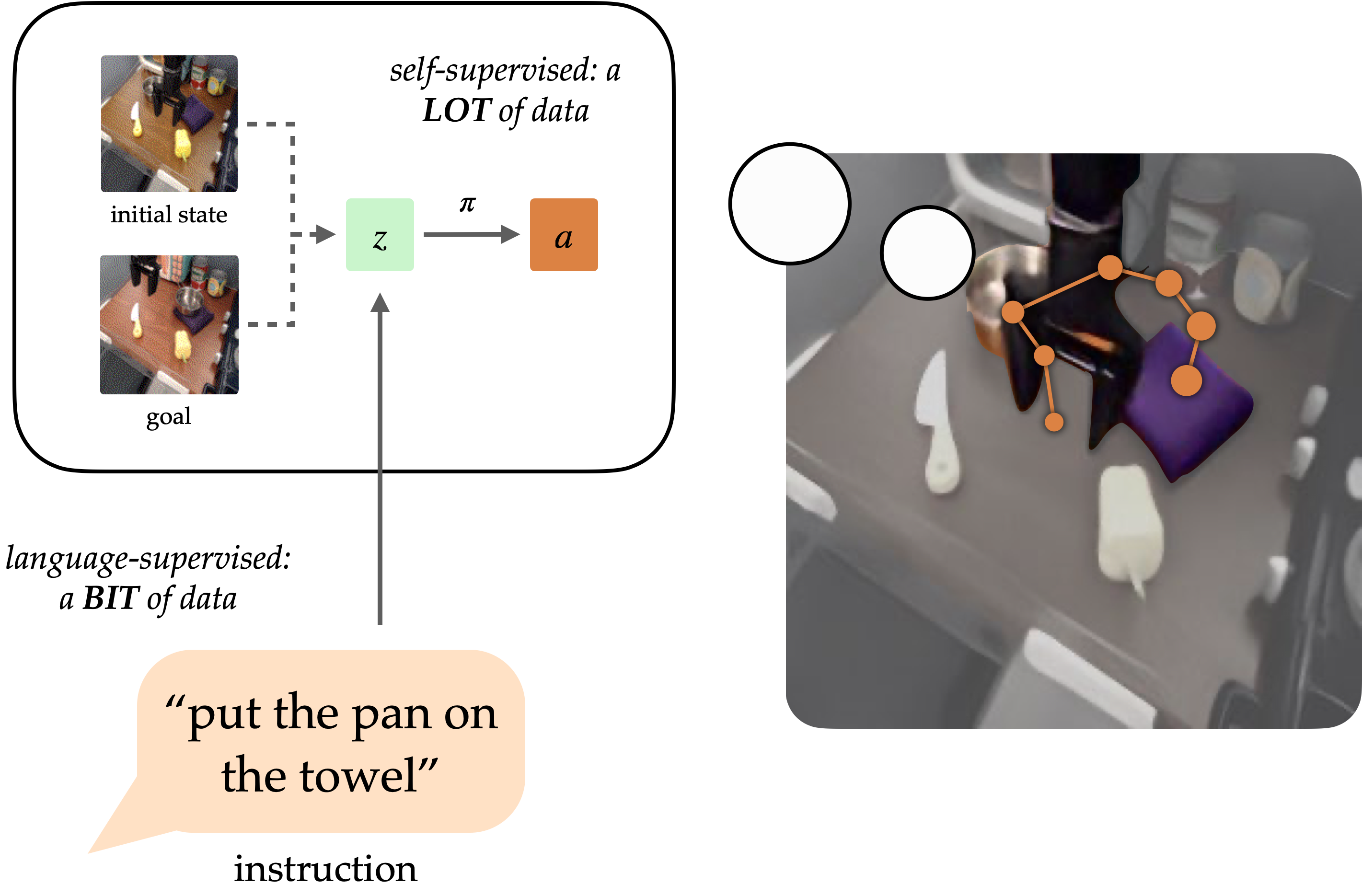
GRIF Model
The GRIF model consists of a language encoder, a goal encoder, and a policy network. The encoders map language instructions and goal images into a shared task representation space, which conditions the policy network when predicting actions. The model can be conditioned on either language instructions or goal images to predict actions, but we primarily use goal-conditioned training to improve the language-conditioned use case.
GRIF is trained jointly with language-conditioned behavioral cloning (LCBC) and goal-conditioned behavioral cloning (GCBC). The labeled dataset contains both language and goal task specifications, so we use it to supervise both the language- and goal-conditioned predictions. The unlabeled dataset contains only goals and is used for GCBC. By sharing the policy network, GRIF enables stronger transfer between the two modalities by requiring that language and goal representations be similar for the same semantic task.
Alignment through Contrastive Learning
Representations between goal-conditioned and language-conditioned tasks are explicitly aligned through contrastive learning. The alignment structure is learned through an infoNCE objective on instructions and images from the labeled dataset. Dual image and text encoders are trained using contrastive learning on matching pairs of language and goal representations.
To address the limitations of existing vision-language models, we modify the CLIP architecture to accommodate and fine-tune it for aligning task representations. This modification allows CLIP to operate on pairs of state and goal images and preserves the pre-training benefits from CLIP.
Robot Policy Results
The GRIF policy is evaluated in the real world on 15 tasks across 3 scenes. GRIF shows the best generalization and strong manipulation capabilities. It is able to ground language instructions and carry out tasks even when multiple tasks are possible in the scene.
Conclusion
GRIF enables a robot to utilize large amounts of unlabeled trajectory data to learn goal-conditioned policies while providing a language interface to these policies via aligned language-goal task representations. Our experiments demonstrate that GRIF can effectively leverage unlabeled robotic trajectories, with large improvements in performance over baselines and methods that only use language-annotated data.
GRIF has limitations that could be addressed in future work, such as handling qualitative instructions and incorporating human video data for richer semantics. However, GRIF offers practical solutions for instruction following and can redefine the way companies work with AI.
If you want to evolve your company with AI and stay competitive, consider using Goal Representations for Instruction Following. Discover how AI can redefine your way of work, identify automation opportunities, define KPIs, select an AI solution, and implement gradually. For AI KPI management advice, connect with us at hello@itinai.com. And for continuous insights into leveraging AI, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.
Spotlight on a Practical AI Solution
Consider the AI Sales Bot from itinai.com/aisalesbot designed to automate customer engagement 24/7 and manage interactions across all customer journey stages. Discover how AI can redefine your sales processes and customer engagement. Explore solutions at itinai.com.
List of Useful Links:
- AI Lab in Telegram @aiscrumbot – free consultation
- Goal Representations for Instruction Following
- The Berkeley Artificial Intelligence Research Blog
- Twitter – @itinaicom























