
Understanding Generative Reward Models (GenRM)
What is Reinforcement Learning?
Reinforcement Learning (RL) helps AI learn by interacting with its environment. It uses rewards for good actions and penalties for bad ones. A new method called Reinforcement Learning from Human Feedback (RLHF) improves AI by including human preferences in training, ensuring AI aligns with human values.
The Challenge of Human Feedback
Collecting human feedback is costly and time-consuming, creating a bottleneck in AI development. This reliance on human data can limit how well models perform on new tasks they haven’t encountered before, especially in real-world situations.
Introducing RLAIF
Reinforcement Learning from AI Feedback (RLAIF) is an alternative that uses AI-generated feedback instead of human input. However, studies show that AI feedback can sometimes misalign with human preferences, especially in unfamiliar tasks.
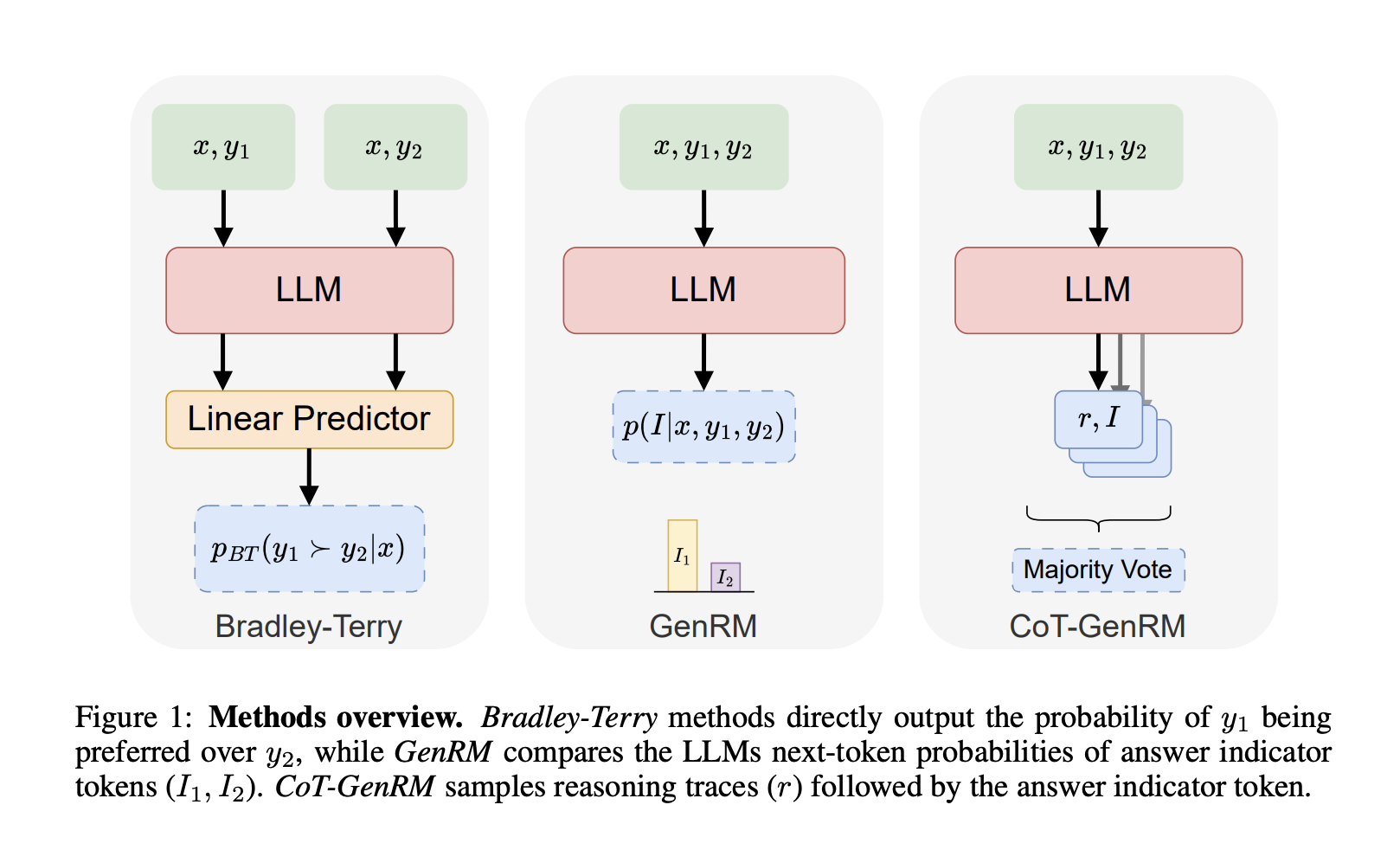
GenRM: A Hybrid Solution
Researchers from SynthLabs and Stanford University developed Generative Reward Models (GenRM). This method combines the best of RLHF and RLAIF, allowing AI to generate its own feedback through reasoning traces. This reduces the need for extensive human feedback while still reflecting human preferences.
How GenRM Works
GenRM uses a large pre-trained language model to create reasoning chains that guide decision-making. This self-generated reasoning acts as feedback, which is refined over time. GenRM outperforms traditional methods, showing 9-31% better accuracy in familiar tasks and 10-45% in unfamiliar tasks.
Key Benefits of GenRM
– **Increased Performance:** GenRM enhances task performance significantly, especially in unfamiliar scenarios.
– **Reduced Dependency on Human Feedback:** AI-generated reasoning replaces the need for large datasets of human feedback, speeding up the process.
– **Improved Generalization:** GenRM excels in handling new tasks, making it more robust in real-world applications.
– **Balanced Approach:** Combining AI and human feedback keeps AI aligned with human values while lowering training costs.
– **Iterative Learning:** Continuous refinement through reasoning chains boosts decision-making accuracy and reduces errors.
Conclusion
Generative Reward Models represent a significant advancement in reinforcement learning. By merging human feedback with AI-generated reasoning, GenRM offers a more efficient way to train models without sacrificing performance. It addresses the challenges of human data collection and enhances the model’s ability to adapt to new tasks, making it a promising solution for future AI systems.
Stay Connected
Check out the research paper for more details. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group for updates. If you appreciate our work, subscribe to our newsletter and join our 50k+ ML SubReddit community.
Upcoming Webinar
Join us on October 29, 2024, for a live webinar on the best platform for serving fine-tuned models: the Predibase Inference Engine.
Transform Your Business with AI
Discover how AI can enhance your operations:
– **Identify Automation Opportunities:** Find customer interaction points that can benefit from AI.
– **Define KPIs:** Ensure measurable impacts on business outcomes.
– **Select an AI Solution:** Choose tools that fit your needs.
– **Implement Gradually:** Start small, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter. Explore how AI can transform your sales processes and customer engagement at itinai.com.

























