
“`html
From LLMs to RAG. Elevating Chatbot Performance. What is the Retrieval-Augmented Generation System and How to Implement It Correctly?
Chances are you’ve already heard about RAG – Retrieval-Augmented Generation. This technology has taken the industry by storm, and for good reason. The emergence of RAG systems is a natural consequence of the popularity of Large Language Models. They make it easier than ever before to create a chatbot – one deeply entrenched in the domain of your company data. It can provide a natural language interface for all the company information that a user would normally have to dig through heaps of internal documents to get.
This saves so much time! Let’s just consider the possibilities:
- A factory worker could ask what an error code means and how to proceed with it, instead of hopelessly skimming through bulky instruction manuals.
- An office worker could check on any policy without pestering HR.
- A retail worker could see whether specific promotions stack together.
And the list goes on.
Why can’t we just use GPT though? Is this ‘RAG’ necessary?
Well, there are issues with using LLMs directly in such cases:
- Hallucinations – while LLMs are great at creating plausible sentences, they may not always be factually correct.
- Lack of confidence – LLM by itself won’t be able to confidently declare how it knows what it says, or how the user can confirm it.
- Domain adaptation – Large Language Models are large. Training them in the specifics of what you want them to know is not a task that comes easily or cheaply!
- Domain drift – Let’s say you managed to train a GPT-like model to know everything about your particular use case. What if the underlying data have changed? Do we have to do everything over again?
There are a lot of risks involved in creating a chatbot using LLMs – thankfully, RAG is here to support us.
What is RAG? Retrieval-Augmented Generation explained
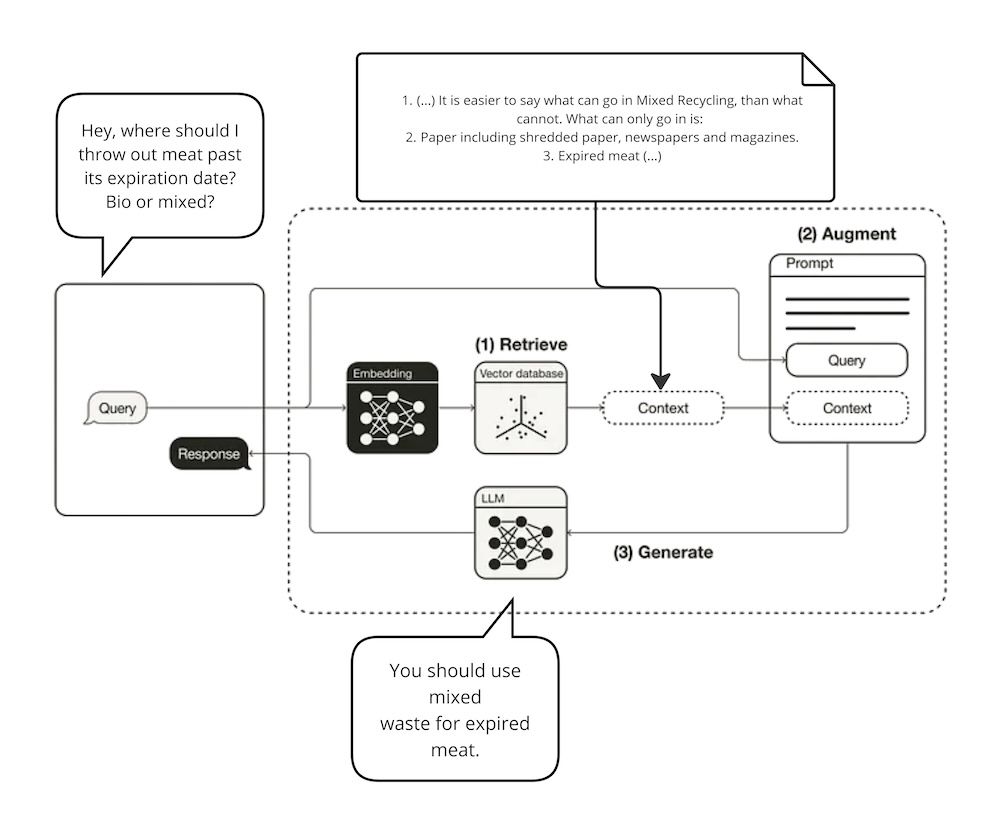
A typical RAG workflow will look like this:
- The user asks a question.
- The question is converted to a numerical representation for convenient processing.
- Pieces of company knowledge similar to the question asked – either semantically, or in terms of keywords – are picked up.
- The relevant text gets packed into the LLM context.
- The LLM is fed the relevant context and user question, and uses it to come up with an accurate answer.
- An exact source and citation are provided for the user, so the truthfulness of the answer can be verified.
What are the benefits of the Retrieval-Augmented Generation?
There are multiple benefits of using Retrieval-Augmented Generation compared to alternative methods of creating chatbots anchored in a specific domain. Amongst the most important ones, we can highlight the following:
- No training necessary
- Fewer hallucinations
- Dynamic knowledge base
- Citations
Building retrieval for your RAG system
Now that we know how retrieval-augmented generation is supposed to work, and what it’s good at, let’s see how to build one.
Embeddings & Vector databases
The first thing you need to do when building an RAG system is to convert your documents to their vector representations and store them somewhere.
Vector databases
Now that we have our embeddings, we need to store them somewhere. Fortunately there is no need to build this storage from the ground up, as there are many refined implementations of vector databases specializing in storing, indexing, serving and performing searches on vectors. Some are even open-source!
Select your vector database
There are many options when it comes to selecting a vector database. Some of the characteristics you may want to pay attention to when making your decision are as follows:
Configuration based on the example of Weaviate
Let’s see how to set up a vector database based on the example of Weaviate, which is one of the most popular providers.
Get accurate citations
LLM wouldn’t make stuff up, would it? Hopefully not, but as Ronald Reagan used to say – trust, but verify.
Learn from our experience – here’s what boosted the performance of our RAG systems
There are A LOT of tricks meant to improve your retrieval performance. This field is growing explosively and produces an unmanageable amount of ideas. Not all of them are all that useful though, and some just aren’t worth the time. When working on commercial projects, we sifted through the internet tips and academic papers to test them all – and a few of the methods tested have proven quite extraordinary.
Summary
RAG systems are great for building chatbots anchored in domain data. They are cheap to build, require no training, and solve a lot of problems inherent to generative models. RAGs validate their answers by providing citations, have a decreased probability of returning hallucinations, and are easy to adapt to a new domain, which makes them a go-to solution for multiple use cases.
Building a solid retrieval mechanism is a cornerstone of any RAG system. Feeding the generative model with accurate and concise context enables it to provide great and informative answers. There is a lot of literature regarding building RAG, and filtering through all the tips and manuals can be time-consuming. We have already checked what works and what doesn’t – as part of successful commercial projects – so make sure to take advantage of a head start and use our tips:
Be mindful when selecting the components: the vectorizer, reranker and the vector database.
Create a benchmarking dataset – not necessarily a huge one – and tune all the retrieval parameters specifically for your use case.
Do not forget to use multiquerying and hierarchical chunking – they give you a lot of ‘bang for your buck’.
With retrieval built this way, you are on a sure path toward a perfect RAG system.
Spotlight on a Practical AI Solution:
Consider the AI Sales Bot from itinai.com/aisalesbot designed to automate customer engagement 24/7 and manage interactions across all customer journey stages.
Discover how AI can redefine your sales processes and customer engagement. Explore solutions at itinai.com.
“`























