
FlashAttention-3: Revolutionizing Attention Mechanisms in AI
Practical Solutions and Value
FlashAttention-3 addresses bottlenecks in Transformer architectures, enhancing performance for large language models and long-context processing applications.
It minimizes memory reads and writes, accelerating Transformer training and inference, leading to a significant increase in LLM context length.
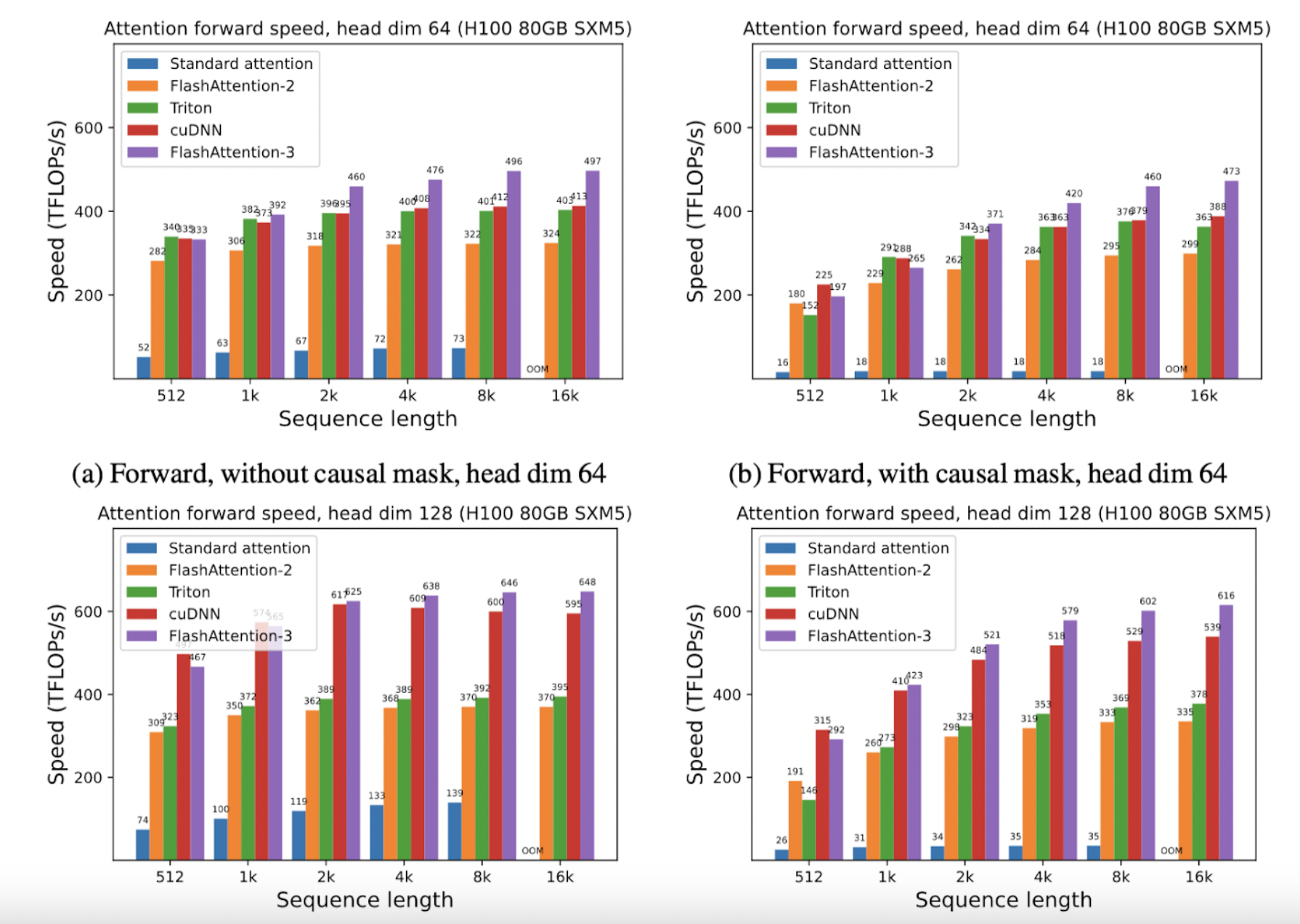
FlashAttention-3 leverages new hardware capabilities in modern GPUs to bridge the gap between potential and actual performance, achieving up to 1.2 PFLOPS with FP8.
It exploits the asynchrony of Tensor Cores and TMA, overlaps computation and data movement, and utilizes low-precision FP8 computations to enhance attention speed on Hopper GPUs.
By utilizing NVIDIA’s CUTLASS library, FlashAttention-3 harnesses Hopper GPUs’ capabilities, unlocking substantial efficiency gains and enabling new model capabilities.
Dao AI Lab has demonstrated how targeted optimizations can lead to significant performance enhancements, aligning algorithmic innovations with hardware advancements.
AI Solutions for Business
Identify Automation Opportunities: Locate key customer interaction points that can benefit from AI.
Define KPIs: Ensure your AI endeavors have measurable impacts on business outcomes.
Select an AI Solution: Choose tools that align with your needs and provide customization.
Implement Gradually: Start with a pilot, gather data, and expand AI usage judiciously.
For AI KPI management advice, connect with us at hello@itinai.com. And for continuous insights into leveraging AI, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.
Explore AI solutions for sales processes and customer engagement at itinai.com.

























