
Practical Business Solutions for Fine-Tuning AI Models
Introduction
This guide outlines how to fine-tune NVIDIA’s NV-Embed-v1 model using the Amazon Polarity dataset. By employing LoRA (Low-Rank Adaptation) and PEFT (Parameter-Efficient Fine-Tuning) from Hugging Face, we can adapt the model efficiently on low-VRAM GPUs without changing all its parameters.
Steps to Implement Fine-Tuning
- Authenticate with Hugging Face to access NV-Embed-v1
- Load and configure the model efficiently
- Apply LoRA fine-tuning using PEFT
- Preprocess the Amazon Polarity dataset for training
- Optimize GPU memory usage
- Train and evaluate the model on sentiment classification
Step-by-Step Implementation
By following these steps, you will successfully fine-tune the NV-Embed-v1 model for binary sentiment classification.
1. Authentication
from huggingface_hub import login
login() # Enter your Hugging Face token when prompted2. Load the Model
import os
HF_TOKEN = "...." # Replace with your actual token
os.environ["HF_TOKEN"] = HF_TOKEN
import torch
from transformers import AutoModel, AutoTokenizer
MODEL_NAME = "nvidia/NV-Embed-v1"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, token=HF_TOKEN)
model = AutoModel.from_pretrained(MODEL_NAME, device_map="auto", torch_dtype=torch.float16, token=HF_TOKEN)3. Configure LoRA
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["self_attn.q_proj", "self_attn.v_proj"],
lora_dropout=0.1,
bias="none",
task_type="FEATURE_EXTRACTION",
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()4. Load and Tokenize Dataset
from datasets import load_dataset
dataset = load_dataset("amazon_polarity")
def tokenize_function(examples):
return tokenizer(examples["content"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)5. Set Up Training Parameters
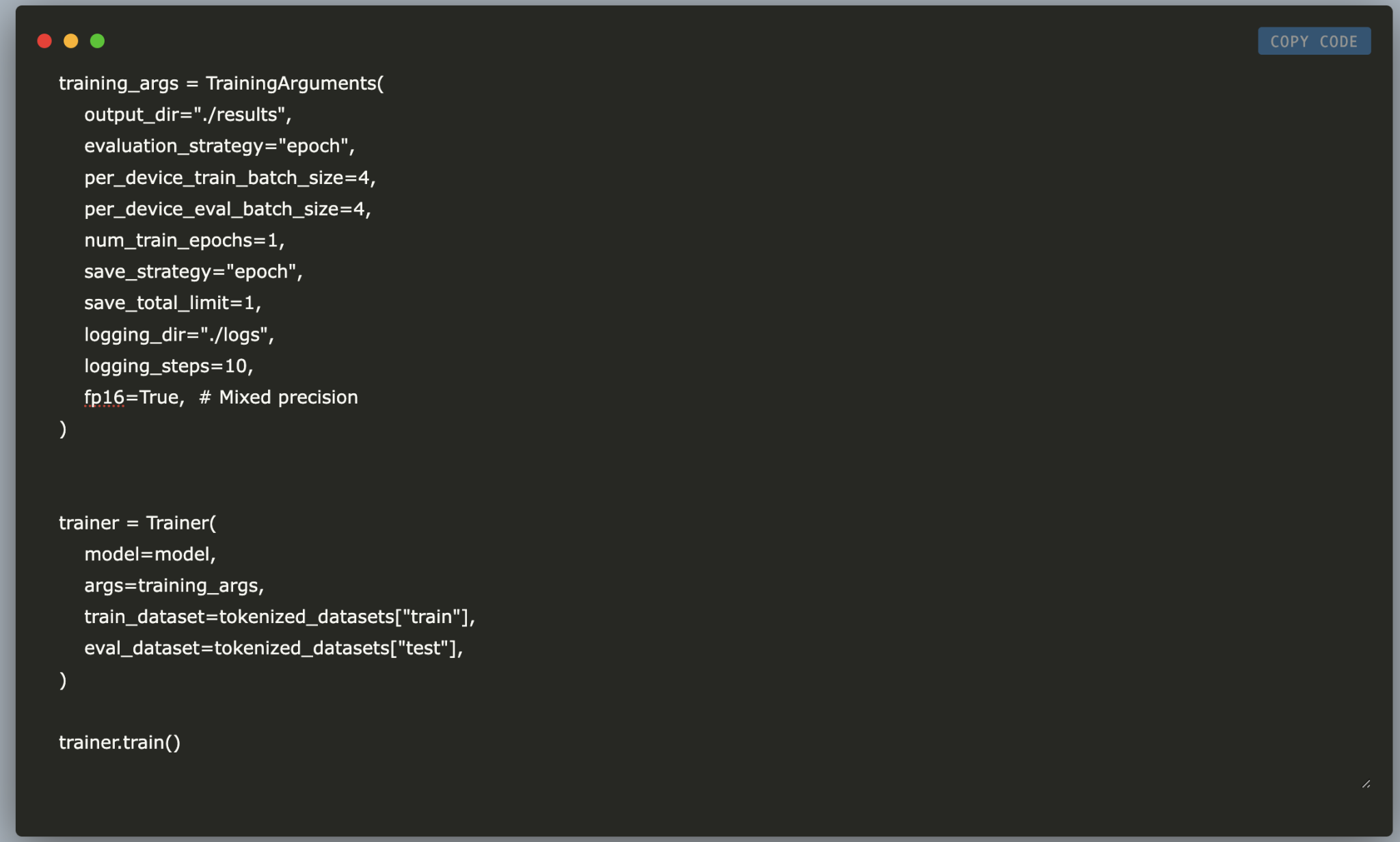
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=1,
save_strategy="epoch",
save_total_limit=1,
logging_dir="./logs",
logging_steps=10,
fp16=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
trainer.train()6. Save the Fine-Tuned Model
model.save_pretrained("./fine_tuned_nv_embed")
tokenizer.save_pretrained("./fine_tuned_nv_embed")
print("Model and tokenizer saved successfully.")Conclusion
By the end of this tutorial, you will have a fine-tuned NV-Embed-v1 model that is optimized for sentiment analysis. This process demonstrates how efficient fine-tuning techniques can be applied to real-world NLP tasks, enabling affordable adaptation of large models for various applications like product review classification and AI-driven recommendation systems.
Next Steps
Explore how artificial intelligence can transform your business processes. Identify opportunities for automation, monitor key performance indicators, and select suitable tools to enhance your objectives. Start with small projects to evaluate effectiveness before scaling your AI initiatives.
Contact Us
If you need guidance on managing AI in business, please contact us at hello@itinai.ru.
“`

























