
Introduction to FASTCURL
The recent introduction of FASTCURL, a Curriculum Reinforcement Learning Framework, marks a significant advancement in training R1-like reasoning models. These models excel in complex problem-solving, particularly in areas requiring deep and coherent reasoning, such as advanced mathematics and logical tasks.
Challenges in Training R1-like Models
One of the primary challenges in training these models is the extensive computational resources required for reinforcement learning, especially when dealing with long context windows. Tasks that necessitate multi-step logic often lead to lengthy outputs, which not only consume significant resources but also slow down the learning process. Furthermore, many of these lengthy outputs do not contribute meaningfully to accuracy, resulting in inefficiencies that hinder effective scaling of training.
Case Study: DeepScaleR
Previous models, such as DeepScaleR, attempted to tackle these challenges by employing a staged context length extension strategy. This model starts with an 8K context window and gradually expands to 24K over three training phases. Despite its improvements, DeepScaleR still requires approximately 70,000 A100 GPU hours, making it a costly and complex solution.
FASTCURL: A Solution for Efficient Training
Researchers at Tencent have developed FASTCURL to address the inefficiencies associated with traditional reinforcement learning training. This innovative method adopts a curriculum-based strategy that aligns with context window expansion. By categorizing the dataset based on input prompt length into short, long, and combined segments, FASTCURL enables a structured training progression.
Training Stages
FASTCURL’s training process unfolds in four distinct stages:
- Stage 1: Training begins with short prompts using an 8K context window.
- Stage 2: The model transitions to a mixed dataset with a 16K window length.
- Stage 3: Training continues with the long dataset, maintaining the 16K window.
- Stage 4: The model reviews the combined dataset again.
This structured approach allows the model to master simple reasoning before progressing to more complex tasks, significantly enhancing training efficiency.
Performance Evaluation
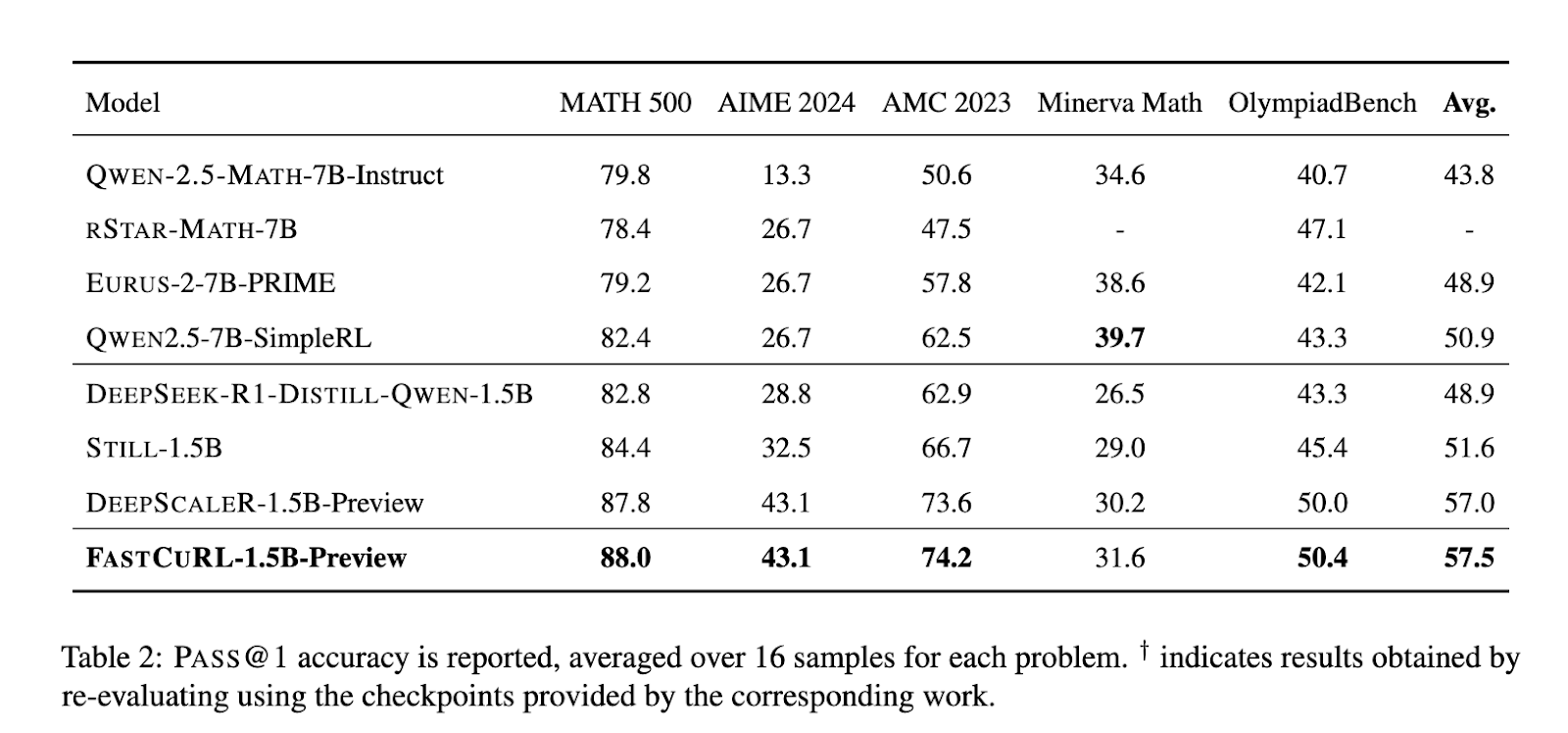
FASTCURL-1.5B-Preview has demonstrated remarkable performance improvements across five benchmarks, outpacing previous models such as DeepScaleR. For instance, it scored:
- 88.0 on MATH 500
- 43.1 on AIME 2024
- 74.2 on AMC 2023
- 31.6 on Minerva Math
- 50.4 on OlympiadBench
With an average PASS@1 score of 57.5, FASTCURL outperformed DeepScaleR, which achieved an average of 57.0 across the same datasets.
Conclusion
The research surrounding FASTCURL highlights a significant computational challenge in training R1-like reasoning models and proposes a practical solution through a curriculum-based training framework. By effectively combining data segmentation and context expansion, FASTCURL not only enhances performance but does so with reduced training time and resource requirements. This approach proves that strategic design in training can be as impactful as raw computational power.


























