
Large language models (LLMs) like Llama 2 have gained popularity among developers, scientists, and executives. Llama 2, recently released by Meta, can be fine-tuned on AWS Trainium to reduce training time and cost. The model uses the Transformer’s decoder-only architecture, has three sizes, and pre-trained models are trained on 2 trillion tokens. Distributed training is supported using NeMo Megatron for Trainium. Fine-tuning experiments were conducted on the Llama 7B model, showing promising results. Trainium is a high-performance and cost-effective option for fine-tuning Llama 2.
Large language models (LLMs) like Llama 2 have gained popularity in various industries for applications such as question answering, summarization, translation, and more. In this article, the authors discuss how to fine-tune Llama 2 on AWS Trainium, a purpose-built accelerator for LLM training, to reduce training times and costs.
Llama 2 is a model that uses the Transformer’s decoder-only architecture and comes in three sizes: 7 billion, 13 billion, and 70 billion parameters. It has a longer context length compared to Llama 1 and uses grouped-query attention in the largest size. The pre-trained models have been trained on a large number of tokens and fine-tuned with human annotations.
To train Llama 2, the authors implemented a script using NeMo Megatron for Trainium, which supports data parallelism, tensor parallelism, and pipeline parallelism. The training environment uses a multi-instance cluster managed by the SLURM system. The training procedure involves downloading the model and training datasets, preprocessing the data, compiling the model, launching the training job, and monitoring the progress using TensorBoard.
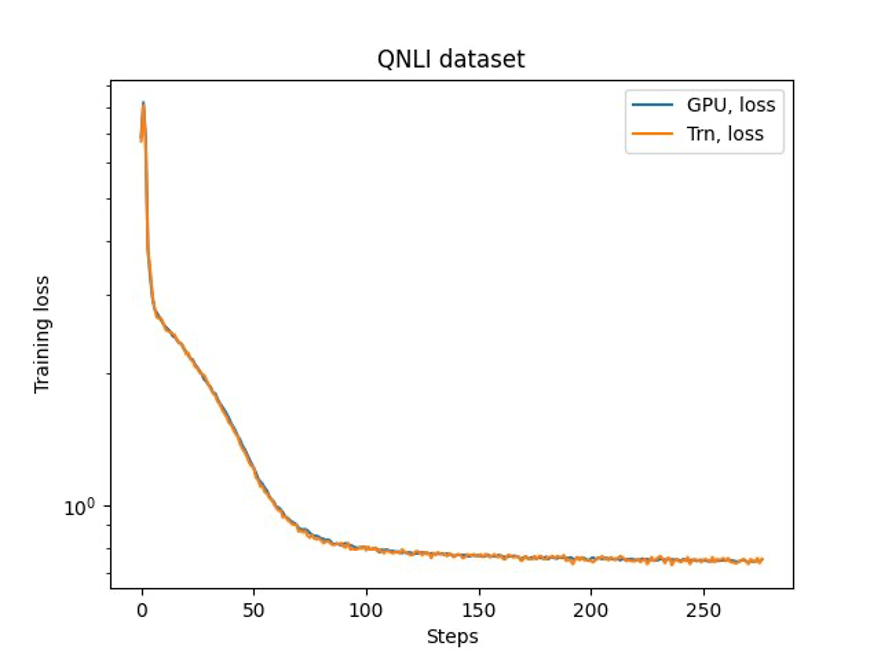
The authors also conducted fine-tuning experiments on the 7B model using the OSCAR and QNLI datasets. They optimized some configurations for training efficiency and adopted a full fine-tuning strategy. They achieved high throughput with distributed training, and the throughput scaled almost linearly as the number of instances increased.
Finally, the authors verified the accuracy of the trained model and compared the training curves between GPU and Trainium. They concluded that Trainium delivers high performance and cost-effective fine-tuning of Llama 2.
Note: The rephrased text has been simplified for clarity.
Action items from meeting notes:
1. Download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer.
Assignee: Data Science team2. Compile the Llama 2 model.
Assignee: DevOps team3. Launch the training job with the optimized script for Llama 2.
Assignee: Data Science team4. Monitor training progress using TensorBoard.
Assignee: Data Science team5. Verify the accuracy of the base model.
Assignee: Data Science team6. Explore resources on using Trainium for distributed pre-training and fine-tuning with NeMo Megatron.
Assignee: Research team7. Update the documentation and tutorial materials for Llama 7B fine-tuning.
Assignee: Technical writing teamPlease note that the specific assignments may vary depending on the organizational structure and responsibilities within your team.
List of Useful Links:
- AI Scrum Bot – ask about AI scrum and agile
- Fast and cost-effective LLaMA 2 fine-tuning with AWS Trainium
- AWS Machine Learning Blog
- Twitter – @itinaicom






















