
Practical Solutions and Value of FaithEval Benchmark in Evaluating Contextual Faithfulness in LLMs
Highlights:
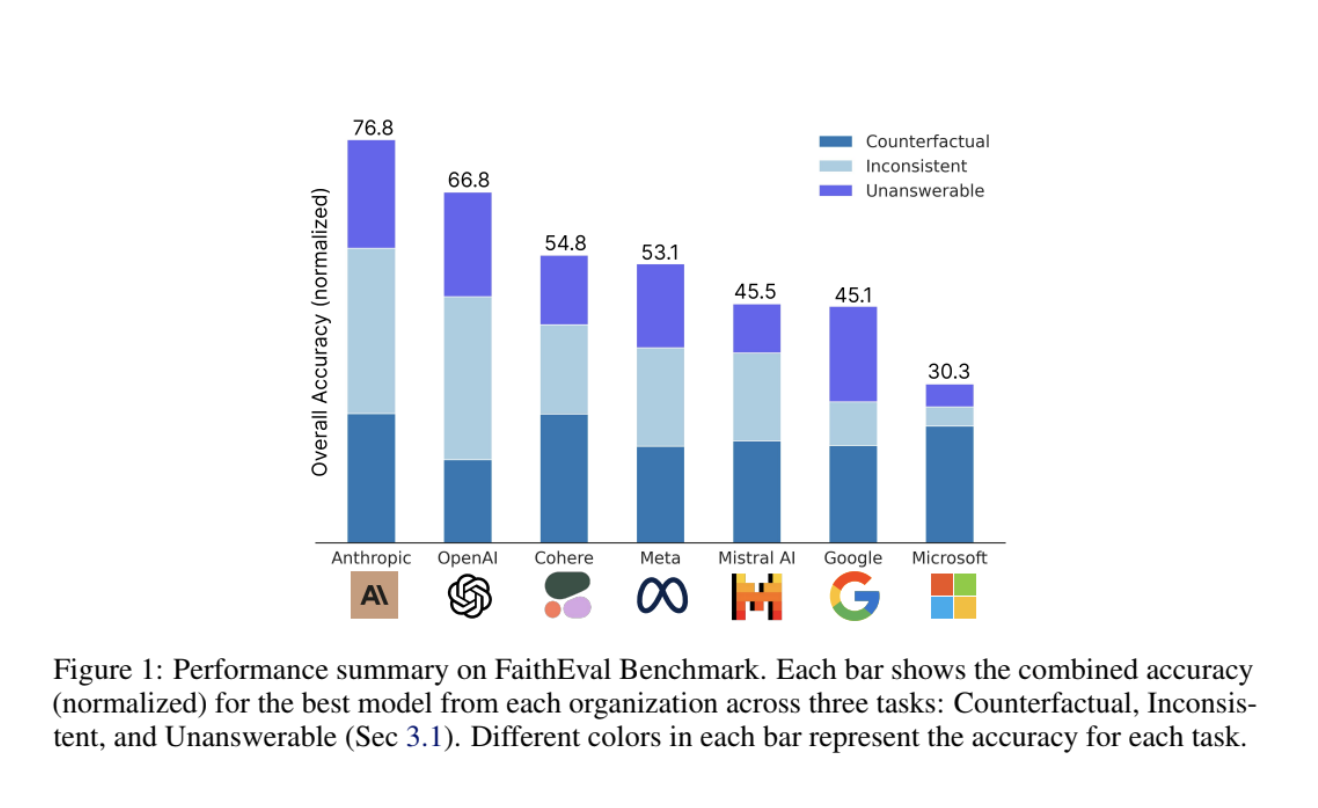
– **Advanced Benchmark**: FaithEval evaluates how well large language models (LLMs) maintain faithfulness to context.
– **Unique Scenarios**: Tests LLMs in unanswerable, inconsistent, and counterfactual contexts.
– **Insights Revealed**: Shows performance drops in adversarial contexts and challenges the notion that larger models always perform better.
– **Call for Advancements**: Emphasizes the need for enhanced benchmarks to evaluate faithfulness accurately.
Value Proposition:
– FaithEval provides a robust framework to assess LLMs in real-world scenarios.
– Reveals limitations of current benchmarks and calls for improved evaluation methods.
– Crucial for ensuring LLMs generate reliable outputs in critical applications.
Key Recommendations:
– **Identify Automation Opportunities**: Locate customer interaction points suitable for AI integration.
– **Define Measurable KPIs**: Ensure AI initiatives impact business outcomes.
– **Select Tailored AI Solutions**: Pick tools that meet specific business needs and offer customization.
– **Implement AI Gradually**: Start with a pilot, collect data, and expand AI use strategically.
If you are interested in enhancing your company with AI, leverage FaithEval to drive competitive advantage and improve contextual faithfulness in LLMs. Reach out to us at hello@itinai.com for AI KPI management advice or stay updated on AI insights via our Telegram t.me/itinainews or Twitter @itinaicom.
























