
Practical Solutions and Value of FACTALIGN Framework
Enhancing Factual Accuracy and Helpfulness of LLMs
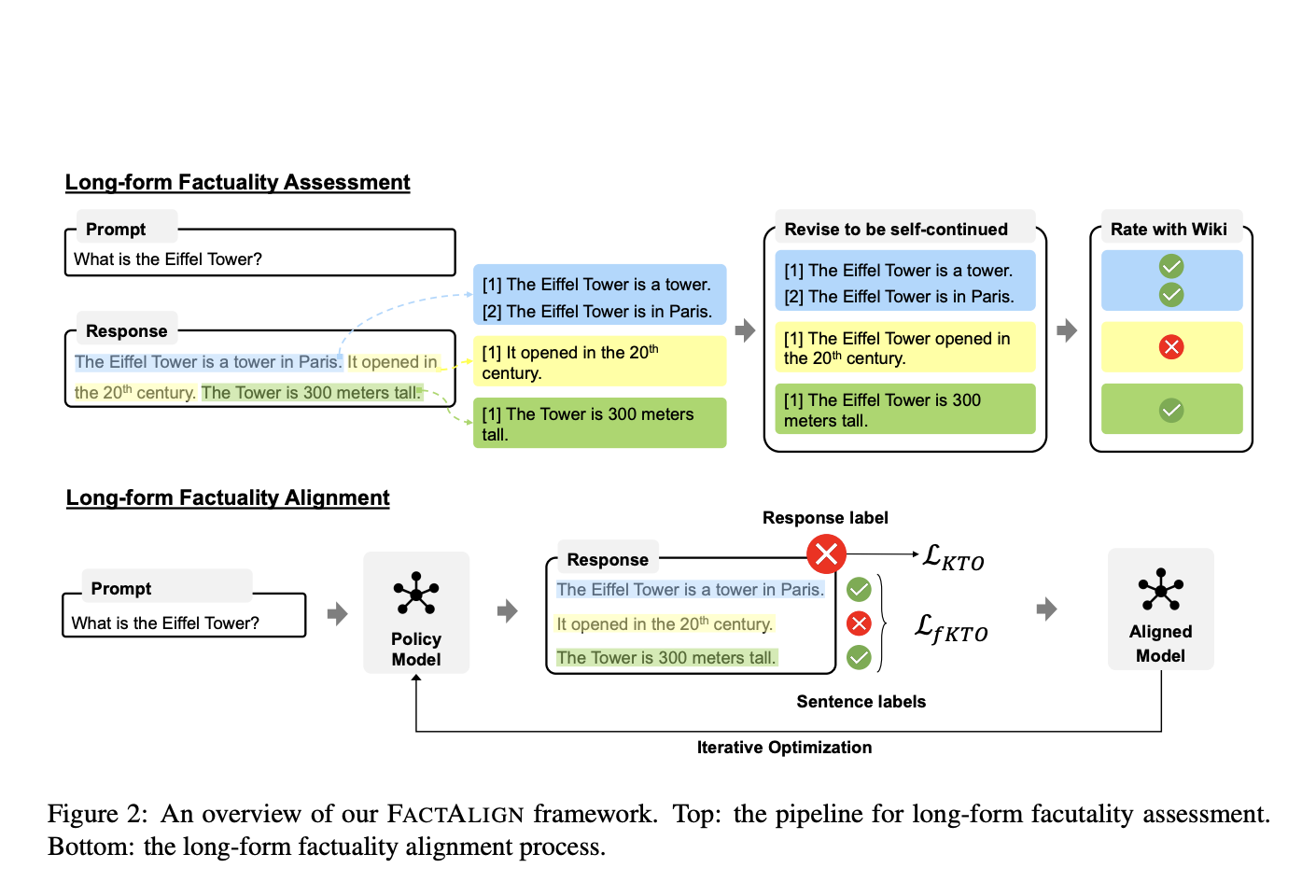
LLMs, like GPT models, can struggle with generating accurate content, especially in long-form responses. FACTALIGN offers a solution by improving factual accuracy without compromising helpfulness.
FACTALIGN introduces fKTO, an alignment algorithm that enhances factuality by aligning LLM responses with fine-grained factual assessments. This boosts factual accuracy while maintaining the usefulness of the responses.
Experiments demonstrate that FACTALIGN significantly improves factual accuracy, as shown by increased factual F1 scores. The framework addresses challenges like hallucination and non-factual content, making LLM responses more reliable.
Iterative Optimization for Continuous Improvement
FACTALIGN employs an iterative optimization process to enhance alignment between responses and factual assessments. By periodically assessing new responses and updating the training dataset, the framework ensures continuous improvement in factual accuracy and helpfulness.
Performance Boost and Comparative Analysis
Comparative experiments show that FACTALIGN outperforms models like GPT-4-Turbo and LLaMA-2-70B-Chat, significantly enhancing factuality and helpfulness. The framework improves factual recall and precision, demonstrating its effectiveness in enhancing LLM responses.
Control Over Factual Precision and Recall Levels
FACTALIGN provides precise control over factual precision and recall levels in LLM outputs. By integrating data construction and the fKTO alignment algorithm, the framework ensures that LLM responses are both factually accurate and helpful.
Significant Improvement in Accuracy of LLM Responses
FACTALIGN addresses issues like hallucination and non-factual content, leading to a notable improvement in the accuracy of LLM responses to open-domain and information-seeking prompts. This enables LLMs to provide richer information while maintaining factual integrity.
























