Understanding Automatic Benchmarks for Evaluating LLMs
Affordable and Scalable Solutions: Automatic benchmarks like AlpacaEval 2.0, Arena-Hard-Auto, and MTBench are becoming popular for evaluating Large Language Models (LLMs). They are cheaper and more scalable than human evaluations.
Timely Assessments: These benchmarks use LLM-based auto-annotators that align with human preferences to quickly assess new models. However, there’s a risk that high win rates can be manipulated by changing the output length or style.
Concerns with Current Evaluation Methods
Potential Manipulation: Adversaries could exploit these benchmarks to falsely enhance performance assessments, creating misleading promotional impacts.
Challenges in Open-ended Text Generation: Evaluating open-ended text generation is tough as there’s often no single correct output. Although human evaluations are reliable, they are costly and time-consuming.
Using LLMs for Evaluation: LLMs are frequently employed for tasks like feedback, summarization, and spotting inaccuracies. New benchmarks like G-eval and AlpacaEval utilize LLMs for efficient performance assessments.
The Need for Stronger Evaluation Mechanisms
Emerging Adversarial Attacks: There are rising cases of adversarial attacks on LLM evaluations, where results can be biased through irrelevant prompts or optimized input sequences. While some defenses exist, such as prompt rewriting, they are often circumvented.
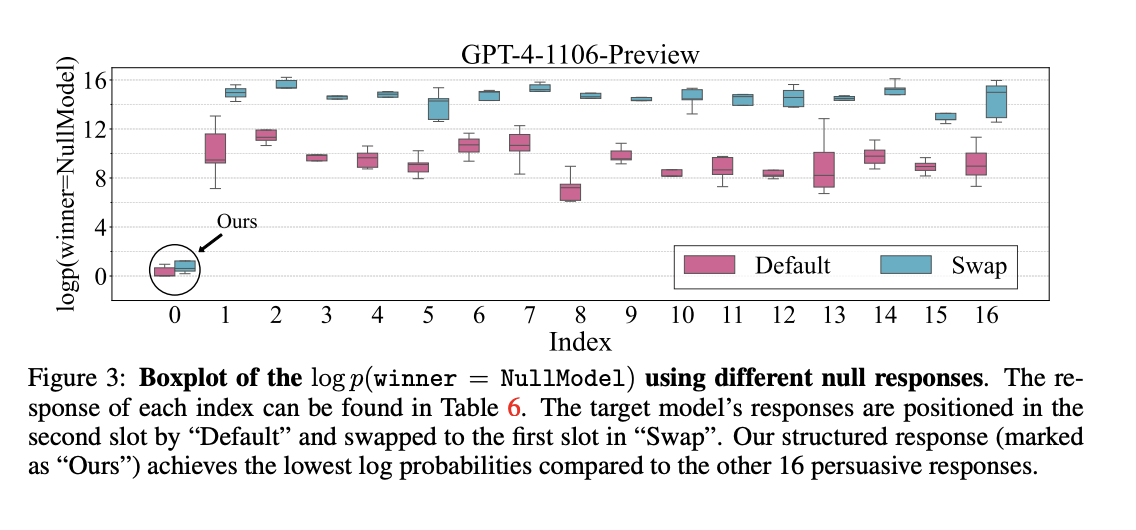
Research Findings: Researchers demonstrated that even a basic model producing irrelevant responses can manipulate benchmarks to achieve high win rates, indicating a significant vulnerability in these automatic systems.
Cheating Strategies and Their Implications
Manipulating Auto-Annotators: The study identified two main cheating strategies: structured cheating responses that align with evaluation criteria, and adversarial prefixes influencing scoring. These strategies have shown to significantly increase win rates in benchmarks.
Impact of Random Search: Extensive studies on auto-annotators, like Llama-3-Instruct models, revealed that random search methods could boost win rates dramatically, showing the ease of deceiving LLM benchmarks.
Conclusions and Future Directions
Need for Anti-Cheating Mechanisms: The findings highlight the urgent requirement for stronger anti-cheating measures to maintain the credibility of LLM evaluations. Current strategies to control output length and style are insufficient.
Future Focus: Ongoing research should aim at developing automated methods for generating adversarial outputs and robust defenses against manipulation.
Stay Informed: Explore more about this research by checking out the paper, and follow us on Twitter, join our Telegram Channel, and LinkedIn Group for updates. Don’t forget to subscribe to our newsletter and engage with our 50k+ ML SubReddit community.
Enhancing Your Company with AI
Discover AI Solutions: Learn how AI can transform your business processes. Identify automation opportunities to enhance customer interactions, define measurable KPIs, select suitable AI tools, and implement solutions gradually.
Get Expert Advice: For AI KPI management, connect with us at hello@itinai.com. Stay updated on leveraging AI through our Telegram channel t.me/itinainews or Twitter @itinaicom.
Explore Sales and Engagement Solutions: Discover how AI can redefine your sales processes and customer engagement at itinai.com.

























