
Practical Solutions for AI Safety and Unlearning Techniques
Challenges in Large Language Models (LLMs) and Solutions:
– **Harmful Content**: **Toxic, illicit, biased, and privacy-infringing material** generated by LLMs.
– **Safety Training**: **DPO and PPO methods** to prevent dangerous information responses.
– **Circuit Breakers**: Utilizing representation engineering to orthogonalize unwanted concepts.
Unlearning as a Solution:
– **Purpose**: **Remove specific knowledge** entirely from models.
– **Methods**: **RMU and NPO** focus on safety-driven unlearning.
– **Challenges**: **Information extraction** risks despite unlearning efforts.
Research Insights:
– **Comparison**: Unlearning vs. Safety Training using **WMDP benchmark**.
– **Evaluation**: White-box testing for **robustness of unlearning methods**.
– **Identified Vulnerabilities**: Limitations in current unlearning techniques.
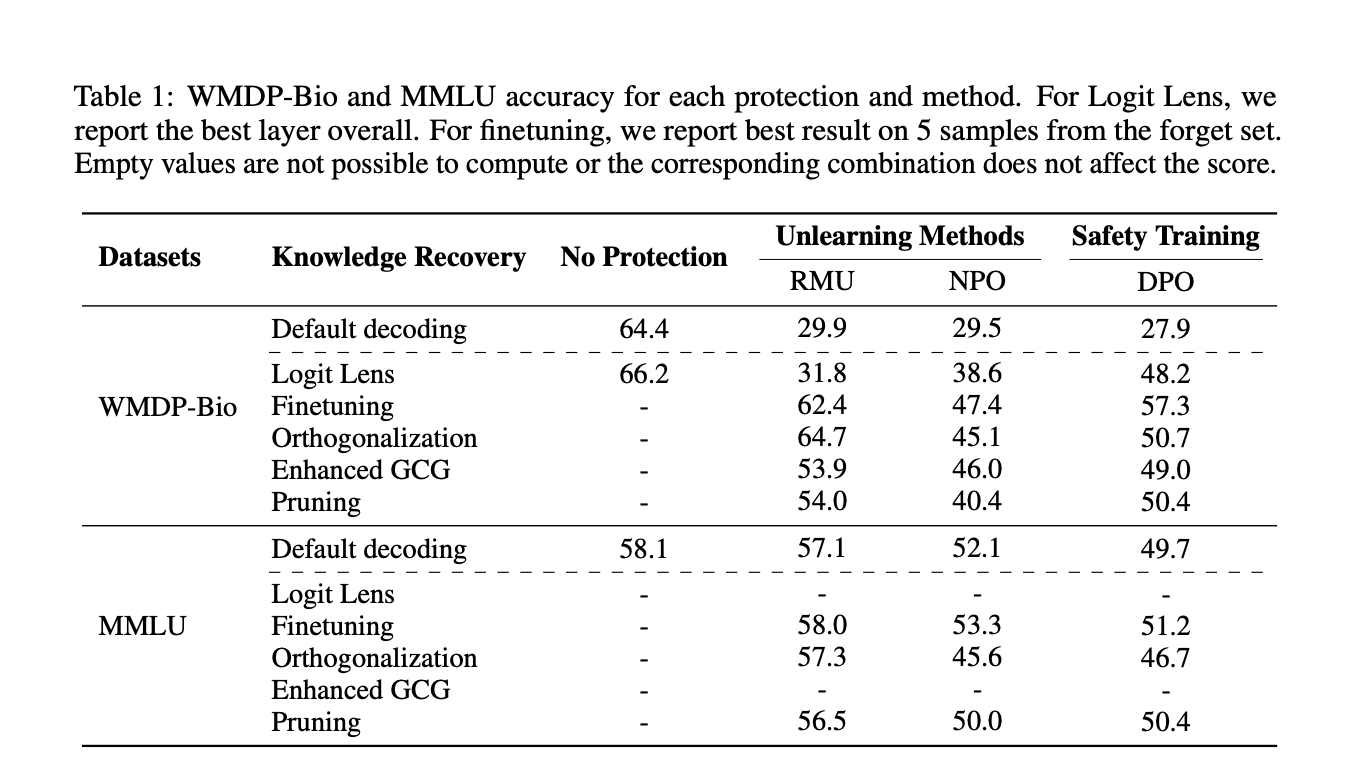
Methods for Evaluating Safety in Unlearned Models:
– **Finetuning**: Utilizing **LoRA** for model adjustments.
– **Orthogonalization**: Removing refusal directions in the activation space.
– **Logit Lens**: Extracting answers from intermediate layers.
– **GCG Optimization**: Preventing hazardous knowledge detection.
– **Set Difference Pruning**: Identifying safety-aligned neurons.
Key Takeaways from the Study:
– **Recovery of Knowledge**: Unlearning not entirely effective in removing hazardous capabilities.
– **Comparison with Safety Training**: Unlearning methods show varying vulnerabilities.
– **Need for Robust Unlearning**: Importance of **enhanced techniques** for safe AI deployment.
AI Implementation Strategies:
– **Identify Automation Opportunities**: Utilize AI at key customer touchpoints.
– **Define Measurable KPIs**: Ensure AI impacts business outcomes.
– **Choose Customized AI Solutions**: Select tools aligned with business needs.
– **Implement Gradually**: Start with pilots and expand AI usage strategically.
Connect with Us:
– **Email**: hello@itinai.com
– **Telegram**: t.me/itinainews
– **Twitter**: @itinaicom























