
Practical AI Solutions for Evaluating LLM Trustworthiness
Assessing Response Reliability
Large Language Models (LLMs) often provide confident answers, but assessing their reliability for factual questions is challenging. We aim for LLMs to yield high trust scores, reducing the need for extensive user verification.
Evaluating LLM Robustness
Methods like FLASK and PromptBench evaluate LLMs’ consistency and resilience to input variations, addressing concerns over vulnerabilities and performance across rephrased instructions. Researchers from VISA introduce an innovative approach to assess the real-time robustness of any black-box LLM, offering a model-agnostic means of evaluating response robustness.
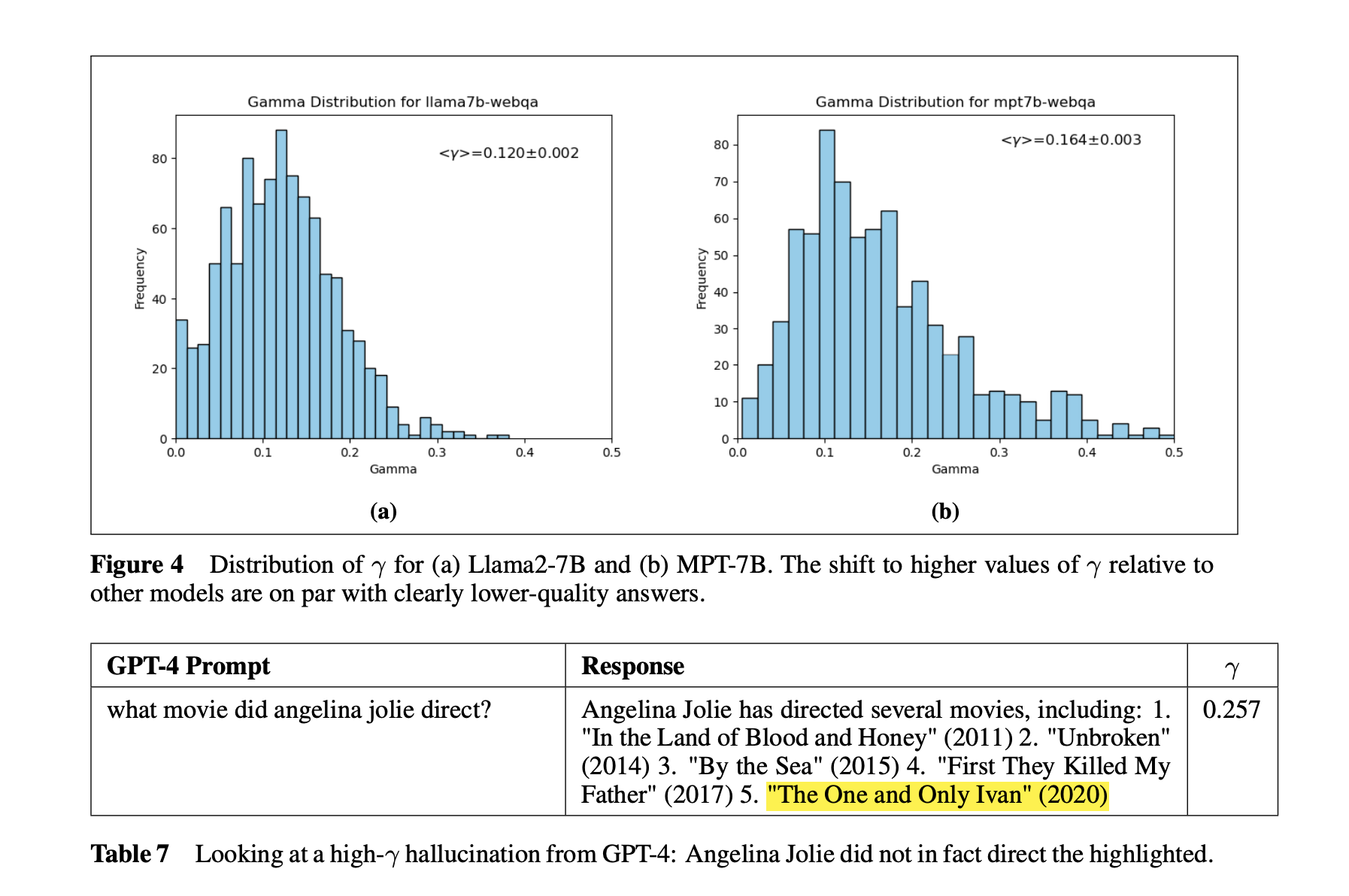
Correlating γ with Human Annotations
Researchers measure the correlation between γ values and trustworthiness across various LLMs and question-answer corpora, providing a practical metric for evaluating LLM reliability. Human ratings confirm that low-γ leaders among the tested models are GPT-4, ChatGPT, and Smaug-72B.
AI for Business Transformation
If you want to evolve your company with AI, stay competitive, and use AI for your advantage, consider the insights from Evaluating LLM Trustworthiness: Insights from Harmoniticity Analysis Research from VISA Team. AI can redefine your way of work by identifying automation opportunities, defining KPIs, selecting AI solutions, and implementing them gradually.
Spotlight on a Practical AI Solution
Consider the AI Sales Bot from itinai.com/aisalesbot designed to automate customer engagement 24/7 and manage interactions across all customer journey stages.

























