
Enhancing Reinforcement Learning Explainability with Temporal Reward Decomposition
Practical Solutions and Value
Future reward estimation in reinforcement learning (RL) is vital but often lacks detailed insights into the nature and timing of anticipated rewards. This limitation hinders understanding in applications requiring human collaboration and explainability.
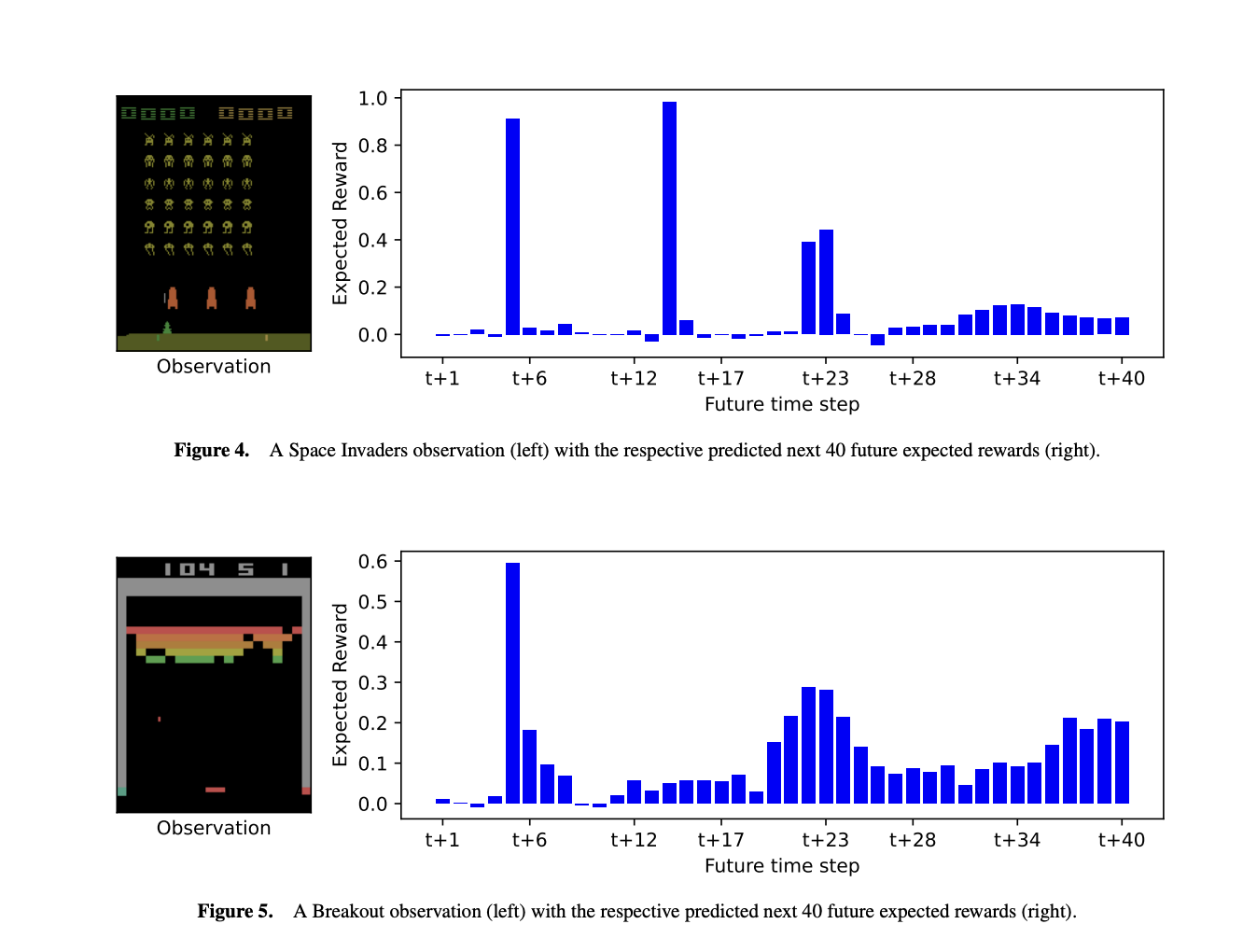
Temporal Reward Decomposition (TRD) enhances explainability in RL by modifying an agent’s future reward estimator to predict the next N expected rewards, revealing when and what rewards are anticipated. TRD integration into existing RL models, such as DQN agents, offers valuable insights into agent behavior and decision-making in complex environments with minimal performance impact.
The approach introduces three methods for explaining an agent’s future rewards and decision-making in reinforcement learning environments, offering new insights into agent behavior and decision-making processes.
TRD reveals more granular details about an agent’s behavior, such as reward timing and confidence, and can be expanded with additional decomposition approaches or probability distributions for future research.
Discover how AI can redefine your way of work. Identify Automation Opportunities, Define KPIs, Select an AI Solution, Implement Gradually. For AI KPI management advice, connect with us at hello@itinai.com.
Discover how AI can redefine your sales processes and customer engagement. Explore solutions at itinai.com.























