
Practical Solutions and Value of Enhancing Large Language Models
Overview
Large language models (LLMs) are crucial for AI, enabling systems to understand and respond to human language. Fine-tuning these models with diverse and high-quality data is essential for real-world applications.
Challenges in Data Selection
Efficiently selecting diverse data subsets for model training is challenging due to the vast amount of available data. Balancing data quality and diversity is key to preventing overfitting and improving generalization.
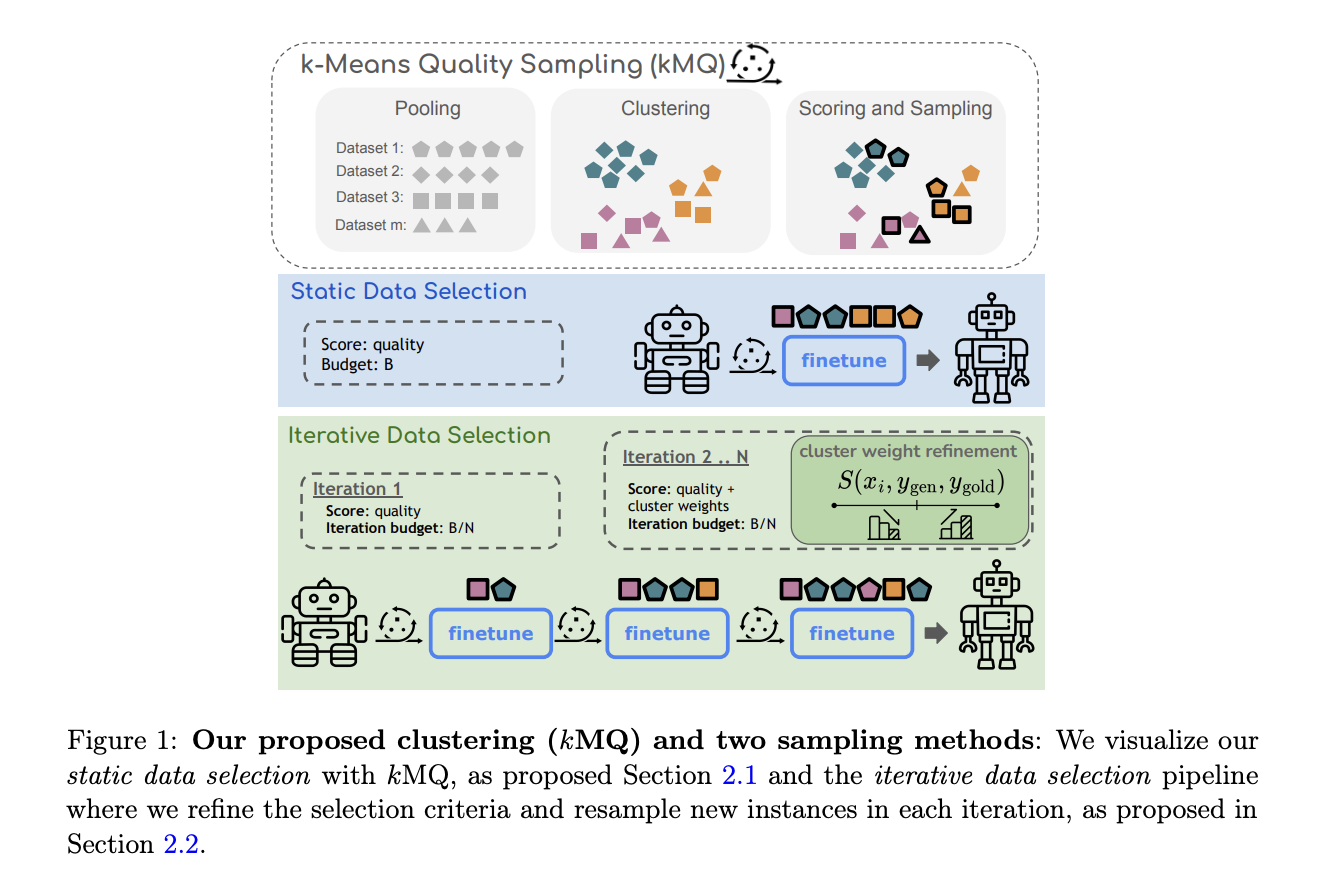
Innovative Data Selection Method
Researchers introduced an iterative refinement method using k-means clustering to prioritize diversity-centric data selection. This approach ensures the model learns from a representative subset of data, enhancing performance across various tasks.
Performance and Results
The kMQ sampling method led to significant performance improvements across tasks like question answering, reasoning, and code generation. It outperformed traditional methods and achieved up to a 7% performance boost.
Practical Applications
The method is scalable, accessible, and cost-effective, making it suitable for various models and datasets. It helps researchers achieve high performance in training LLMs with limited resources.
Conclusion
The research offers an efficient solution for selecting diverse and high-quality data subsets to enhance large language models’ performance. By balancing diversity and quality, the method improves model generalization and task performance.


























