
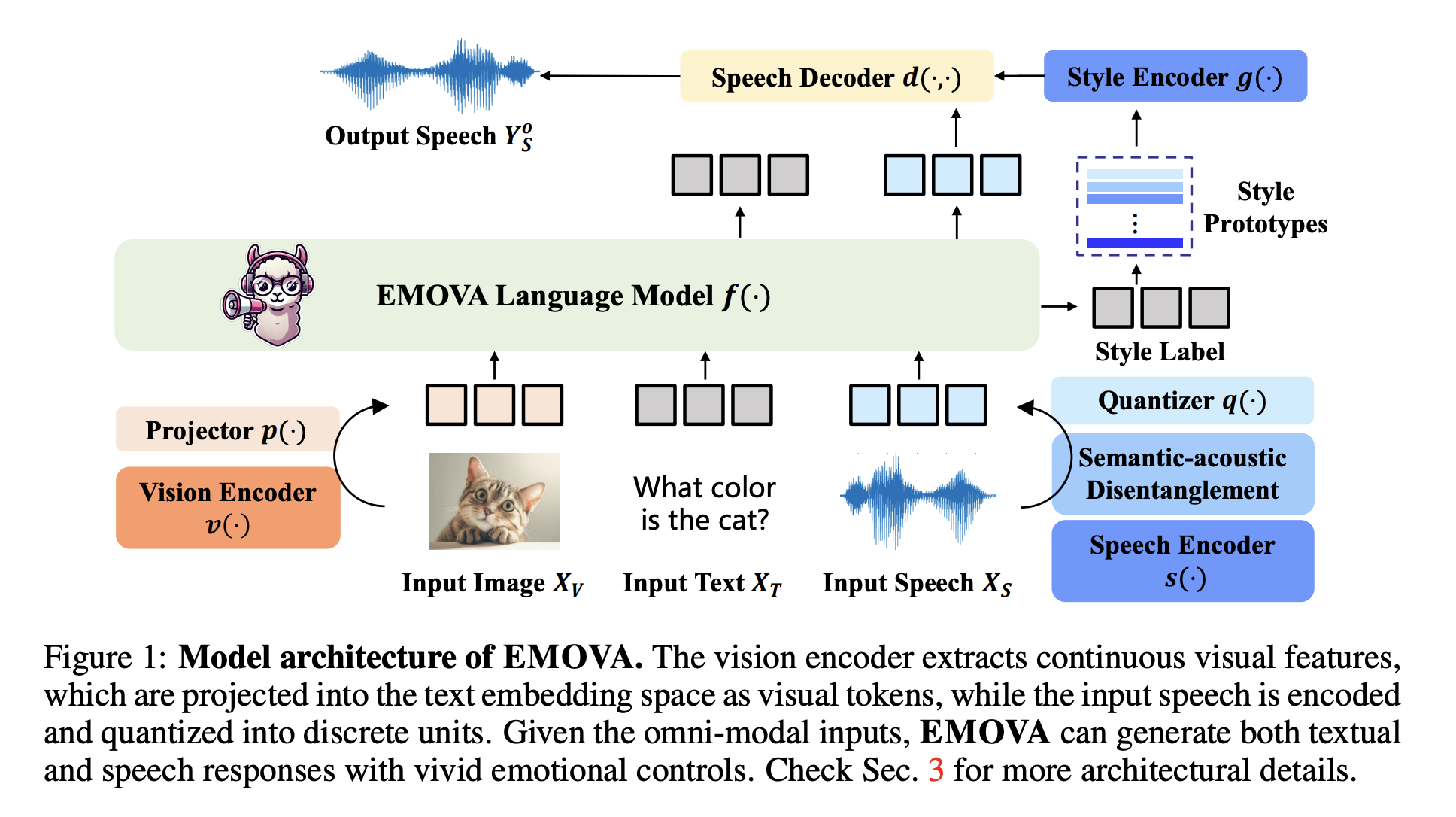
Practical Solutions and Value of EMOVA: A Novel Omni-Modal LLM
Enhancing AI Capabilities
EMOVA integrates vision, language, and speech to enhance interactive capabilities of AI models.
Overcoming Model Limitations
EMOVA addresses the challenge of integrating vision and speech abilities seamlessly in AI models.
Improving Multimodal Models
EMOVA employs a unique architecture to process speech and visual inputs end-to-end, enhancing emotion expression in speech.
Performance and Superiority
EMOVA outperforms existing models in speech-language and vision-language tasks, achieving high accuracy across multiple domains.
Future of AI Development
EMOVA sets a new standard for omni-modal large language models, paving the way for advanced AI interactions and research.
AI Implementation Tips
Implement AI solutions gradually, define KPIs, and choose tools that align with your needs to stay competitive.
Connect with Us
For AI KPI management advice and insights, contact us at hello@itinai.com. Follow us on Telegram or Twitter for continuous updates.
























