
Introduction to Long-Form Video Understanding
Understanding long-form videos, which can last from several minutes to hours, poses significant challenges in the field of computer vision. As the demand for video analysis grows, especially beyond short clips, businesses must find ways to efficiently extract relevant information from lengthy content. The primary challenge lies in identifying a limited number of key frames from the thousands available in a video, which is essential for answering specific queries.
The Challenge of Video Analysis
Traditional Video Language Models (VLMs) like LLaVA and Tarsier often analyze hundreds of tokens per frame, making the frame-by-frame assessment of long videos computationally intensive. This inefficiency has led to the rise of a new approach known as temporal search. Unlike conventional temporal localization that identifies continuous segments, temporal search focuses on retrieving a sparse set of highly relevant frames from the entire video timeline. This method resembles searching for a needle in a haystack.
Limitations of Current Methods
Despite advancements in attention mechanisms and video transformers, existing methods struggle to capture long-range dependencies effectively. Some techniques attempt to compress video data or select specific frames to reduce input size. While benchmarks for long-video understanding exist, they primarily evaluate performance based on question-answering tasks rather than the effectiveness of temporal search itself. Emerging methods that emphasize keyframe selection and fine-grained frame retrieval offer a more efficient approach to understanding long-form video content.
Case Study: LV-HAYSTACK Benchmark
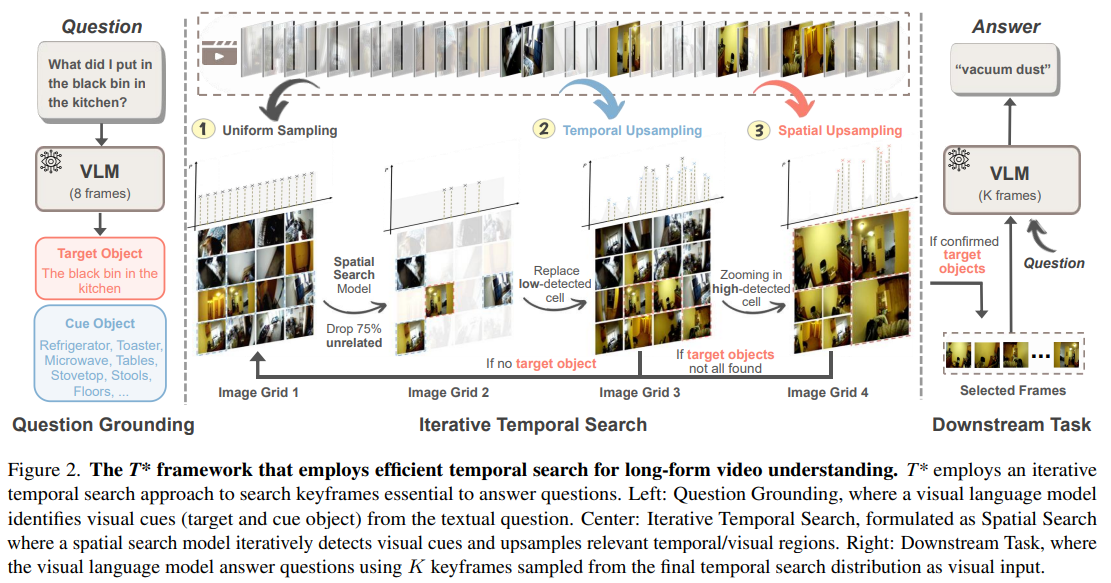
Researchers from Stanford, Northwestern, and Carnegie Mellon have developed LV-HAYSTACK, a comprehensive benchmark consisting of 480 hours of real-world videos and over 15,000 annotated question-answer instances. This benchmark highlights the limitations of current models in identifying key frames and proposes a new framework called T. This innovative framework reimagines temporal search as a spatial search, utilizing adaptive zoom techniques across time and space to enhance performance while reducing computational costs.
Framework Overview: The T Framework
The T framework aims to select minimal keyframes from long videos that retain all necessary information to answer specific questions. It operates in three stages:
- Question Grounding: Identifying relevant objects within the question.
- Iterative Temporal Search: Locating these objects across frames using a spatial search model.
- Task Completion: Updating the frame sampling strategy based on confidence scores.
Evaluated on the LV-HAYSTACK benchmark, the T framework demonstrates improved efficiency and accuracy while significantly reducing computational costs.
Evaluation Across Multiple Datasets
The T framework has been assessed across various datasets and tasks, including LongVideoBench, VideoMME, NExT-QA, EgoSchema, and Ego4D LongVideo QA. Integrated into both open-source and proprietary vision-language models, T consistently enhances performance, particularly in long videos and scenarios with limited frames. By utilizing attention, object detection, or trained models for efficient keyframe selection, T achieves high accuracy while minimizing computational expenses. Experiments reveal that T aligns sampling with relevant frames progressively, approaches human-level performance with more frames, and significantly outperforms traditional sampling methods across numerous evaluation benchmarks.
Conclusion
This research addresses the complexities of long-form video understanding by revisiting temporal search methodologies in leading VLMs. By framing the task as the “Video Haystack” problem, the study emphasizes the need for innovative solutions in identifying key frames from vast video content. The introduction of the LV-HAYSTACK benchmark, alongside the T framework, illustrates a significant leap forward in enhancing video comprehension while maintaining efficiency. The findings affirm that existing methods have considerable room for improvement, and the T framework offers a promising path to overcome these challenges.
For businesses looking to leverage artificial intelligence in video analysis, consider implementing these strategies:
- Explore automation opportunities to streamline processes.
- Identify key performance indicators (KPIs) to measure the impact of AI investments.
- Select customizable tools that align with your business objectives.
- Start with small-scale AI projects, gather effectiveness data, and gradually expand.
For further guidance on managing AI in business, please contact us at hello@itinai.ru or connect with us on Telegram, X, or LinkedIn.


























