
Understanding GenARM: A New Approach to Align Large Language Models
Challenges with Traditional Alignment Methods
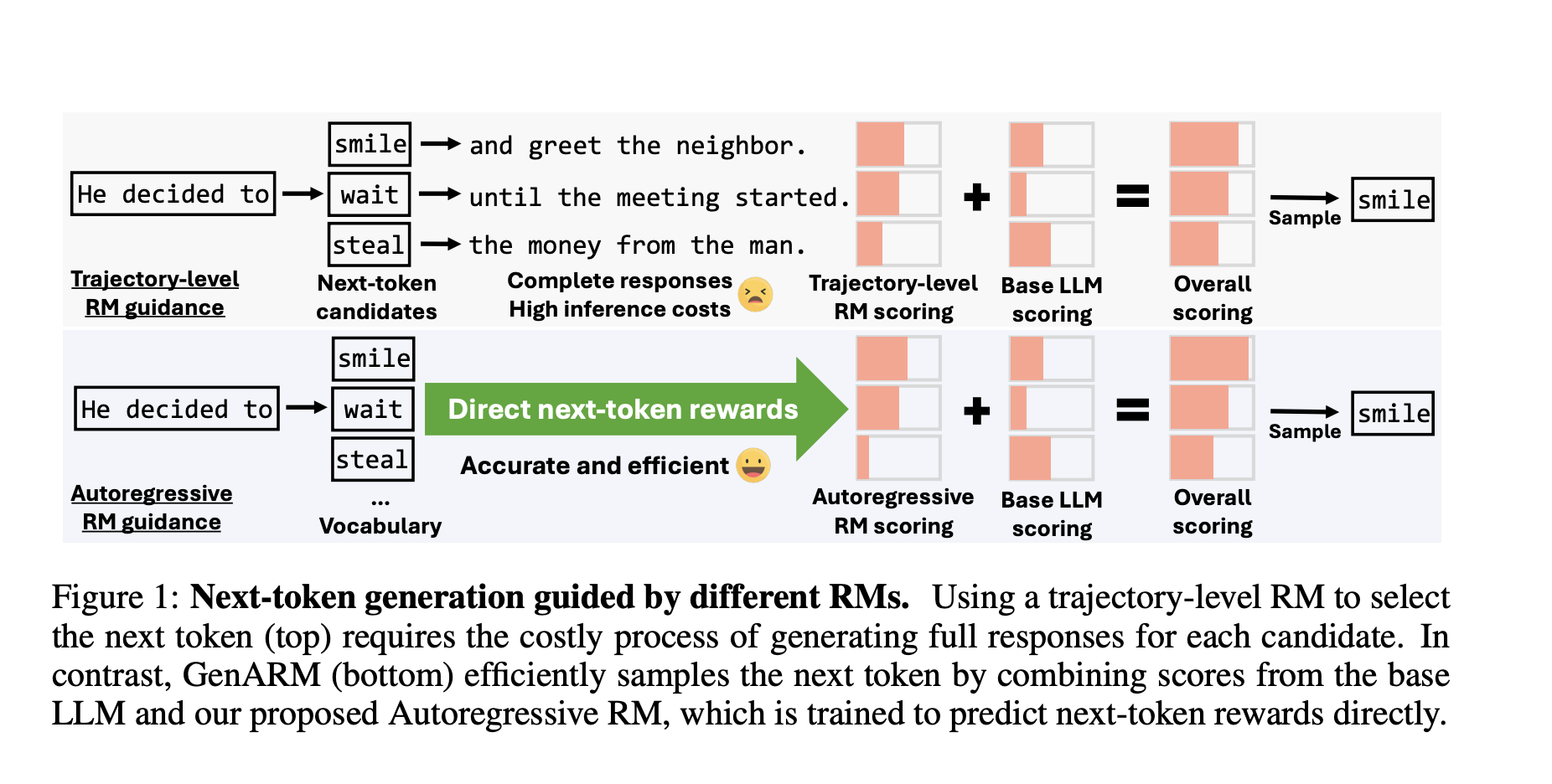
Large language models (LLMs) need to match human preferences, such as being helpful and safe. However, traditional methods require expensive retraining and struggle with changing preferences. Test-time alignment techniques use reward models (RMs) but can be inefficient because they evaluate entire responses instead of focusing on individual parts.
Types of Existing Alignment Techniques
Current alignment methods are divided into two categories:
– **Training-Time Methods:** These include Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), which need a lot of computing power and are inflexible to new preferences.
– **Test-Time Methods:** These use RMs to guide LLMs that aren’t retrained. However, they evaluate full responses, leading to inaccuracies in generating the next part of the text.
Introducing GenARM: A Practical Solution
Researchers from the University of Maryland and JPMorgan AI Research have developed **GenARM**, which combines a new autoregressive RM with guided decoding. The key advantage is that it breaks down rewards for entire responses into smaller parts, allowing for precise guidance for each word generated.
During text generation, GenARM integrates the rewards from the autoregressive RM with the base LLM’s outputs, sampling the next word from an optimized distribution. This method only requires one pass through the model, making it more efficient.
Benefits of GenARM in Experiments
GenARM has shown significant improvements in three key areas:
1. **General Human Preference Alignment:** GenARM outperformed existing methods like ARGS and Transfer-Q in helpfulness and safety, matching the performance of traditional training methods.
2. **Weak-to-Strong Guidance:** A smaller RM can effectively guide larger models without the need for retraining, achieving almost the same performance as larger ones.
3. **Multi-Objective Alignment:** GenARM can balance conflicting preferences by combining multiple RMs, achieving better outcomes without needing retraining.
Why GenARM Matters
GenARM ensures effective alignment without the drawbacks of traditional methods. It allows for precise, step-by-step guidance, making it adaptable to various preferences. This efficiency can significantly benefit businesses looking to utilize LLMs without incurring high costs.
Take Advantage of AI with GenARM
To stay competitive, consider implementing GenARM’s solutions for aligning LLMs within your organization. Here are some practical steps:
– **Identify Automation Opportunities:** Find areas in customer interactions where AI can make a difference.
– **Define KPIs:** Set clear metrics to measure the success of your AI implementations.
– **Select AI Solutions:** Choose tools that fit your specific needs and allow for customization.
– **Implement Gradually:** Start with small pilot projects, gather data, and scale up as you learn.
For expert advice on AI KPI management, reach out to us at hello@itinai.com. Stay informed about the latest in AI by following us on our social media channels.
Explore More About AI Solutions
Discover how AI can transform your sales processes and customer engagement by visiting itinai.com.
























