Advancements in Reinforcement Learning for Large Language Models
Introduction to Reinforcement Learning in LLMs
Recent developments in artificial intelligence have highlighted the potential of reinforcement learning (RL) techniques to enhance large language models (LLMs) beyond traditional supervised fine-tuning. RL enables models to learn optimal responses through reward signals, significantly improving their reasoning and decision-making abilities. This approach aligns more closely with human learning processes, particularly in tasks that require step-by-step problem-solving or mathematical reasoning.
Challenges in Enhancing LLMs
A key challenge in refining LLMs for complex reasoning tasks is ensuring that these models enhance their cognitive abilities rather than simply producing longer outputs. During RL training, a common issue is that models may generate excessively lengthy responses without improving the quality of their answers. This phenomenon raises concerns about optimization biases in RL methods that may prioritize verbosity over accuracy.
Impact of Base Models
Another complication is the inherent reasoning capabilities of some base models, which complicates the assessment of RL’s true impact. Understanding how training strategies and model foundations influence performance is crucial for developing effective AI solutions.
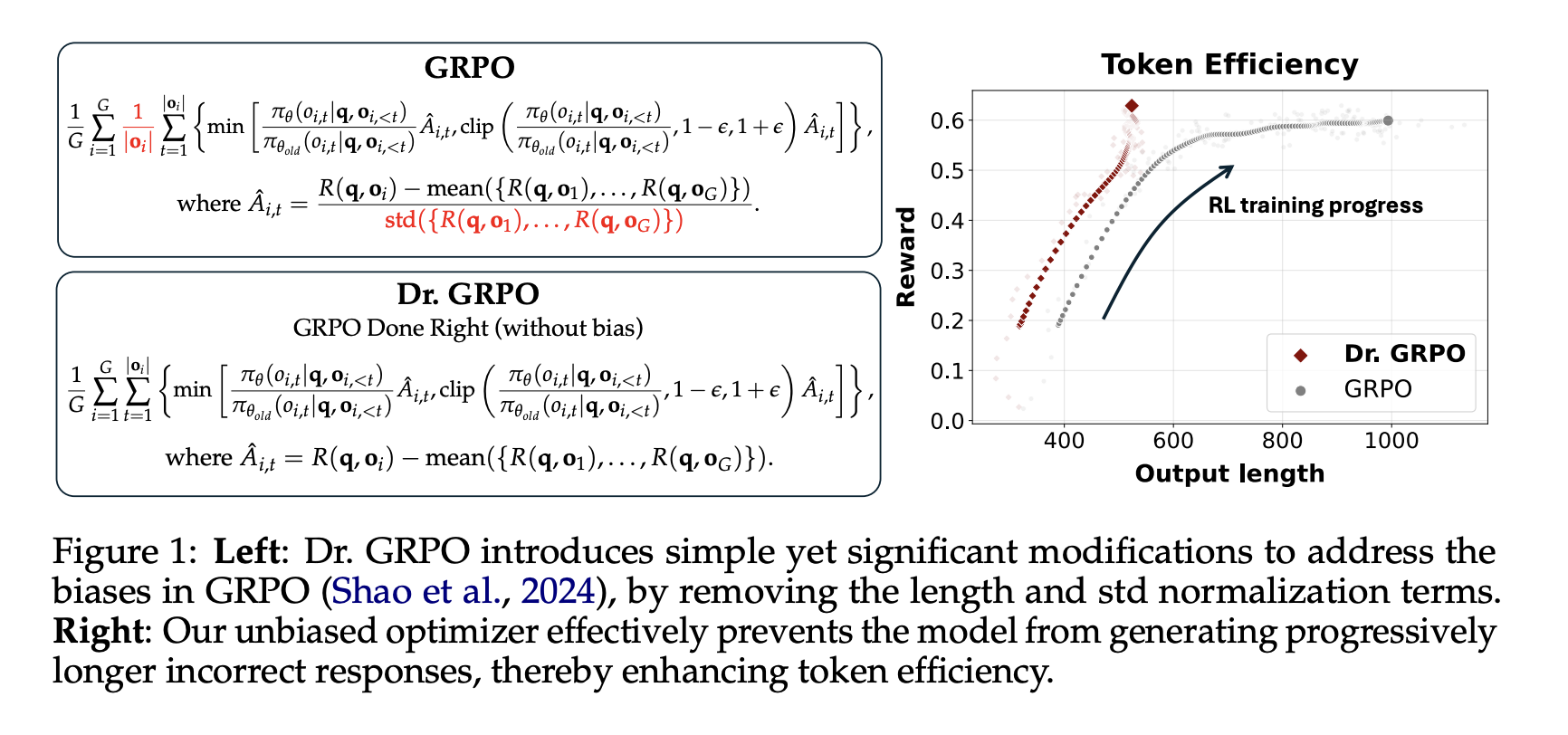
Innovative Approaches: Dr. GRPO
Researchers from Sea AI Lab, the National University of Singapore, and Singapore Management University have introduced a novel method known as Dr. GRPO (Group Relative Policy Optimization Done Right). This approach addresses the biases found in previous RL algorithms by removing problematic normalization terms that affected model updates.
Case Study: Qwen2.5-Math-7B
The Dr. GRPO method was applied to train the Qwen2.5-Math-7B model, which demonstrated remarkable performance on various benchmarks. The training process utilized 27 hours of computing on a modest setup of 8× A100 GPUs, yielding significant results:
- AIME 2024: 43.3% accuracy
- OlympiadBench: 62.7% accuracy
- Minerva Math: 45.8% accuracy
- MATH500: 40.9% accuracy
These results validate the effectiveness of the bias-free RL method, as the model not only performed better but also exhibited more efficient token usage, with incorrect responses being shorter and more focused.
Understanding Pretraining and Model Behavior
The researchers also investigated the characteristics of base models in RL settings. They found that models like Qwen2.5 exhibited advanced reasoning capabilities even before RL fine-tuning, likely due to pretraining on concatenated question-answer data. This complicates the narrative around RL benefits, as improvements may stem from prior training rather than new learning through reinforcement.
Key Findings from the Research
- Models like DeepSeek-V3-Base and Qwen2.5 show reasoning capabilities prior to RL, indicating strong pretraining effects.
- Dr. GRPO effectively eliminates biases by removing length and reward normalization terms.
- The Qwen2.5-Math-7B model achieved impressive benchmark scores, averaging 40.3% across all tests.
- Incorrect responses were shorter and more concise with Dr. GRPO, avoiding unnecessary verbosity.
- Performance varied significantly based on the use of prompt templates, with simpler question sets often yielding better results.
Practical Business Solutions
Organizations looking to leverage AI can implement the following strategies:
- Identify Automation Opportunities: Explore processes that can be automated to enhance efficiency and reduce costs.
- Measure Key Performance Indicators (KPIs): Establish metrics to evaluate the impact of AI investments on business outcomes.
- Select Customizable Tools: Choose AI tools that can be tailored to meet specific business needs.
- Start Small: Initiate with a manageable project, gather data, and gradually expand AI applications.
Conclusion
The study reveals essential insights into the role of reinforcement learning in shaping large language model behavior. It emphasizes the importance of pretraining and the potential biases in popular RL algorithms. The introduction of Dr. GRPO offers a solution to these challenges, leading to more interpretable and efficient model training. With only 27 hours of training, the model achieved state-of-the-art results on major math reasoning benchmarks, reshaping how the AI community should evaluate RL-enhanced LLMs by focusing on method transparency and foundational model characteristics.



