
Integrating Vision and Language in AI
AI has made significant progress by combining vision and language capabilities. This has led to the creation of Vision-Language Models (VLMs), which can analyze both visual and text data at the same time. These models are useful for:
- Image Captioning: Automatically generating descriptions for images.
- Visual Question Answering: Answering questions based on visual content.
- Optical Character Recognition (OCR): Converting images of text into machine-readable text.
- Multimodal Content Analysis: Analyzing content that includes both text and images.
VLMs enhance autonomous systems and improve interactions between humans and computers, as well as streamline document processing. However, handling high-resolution images and various text formats remains a challenge.
Challenges in Current Models
Many existing models struggle with:
- Static Vision Encoders: These models are not flexible enough for high-resolution images.
- Pretrained Language Models: Often inefficient for tasks that involve both vision and language.
- Lack of Diverse Training Data: Many models perform poorly on specialized tasks due to insufficient data variety.
Introducing DeepSeek-VL2 Series
Researchers from DeepSeek-AI have developed the DeepSeek-VL2 series, a new set of open-source VLMs that overcome these challenges. Key features include:
- Dynamic Tiling: Processes high-resolution images effectively, preserving important details.
- Multi-head Latent Attention: Efficiently manages large amounts of text data.
- DeepSeek-MoE Framework: Activates only necessary parameters during tasks for better efficiency.
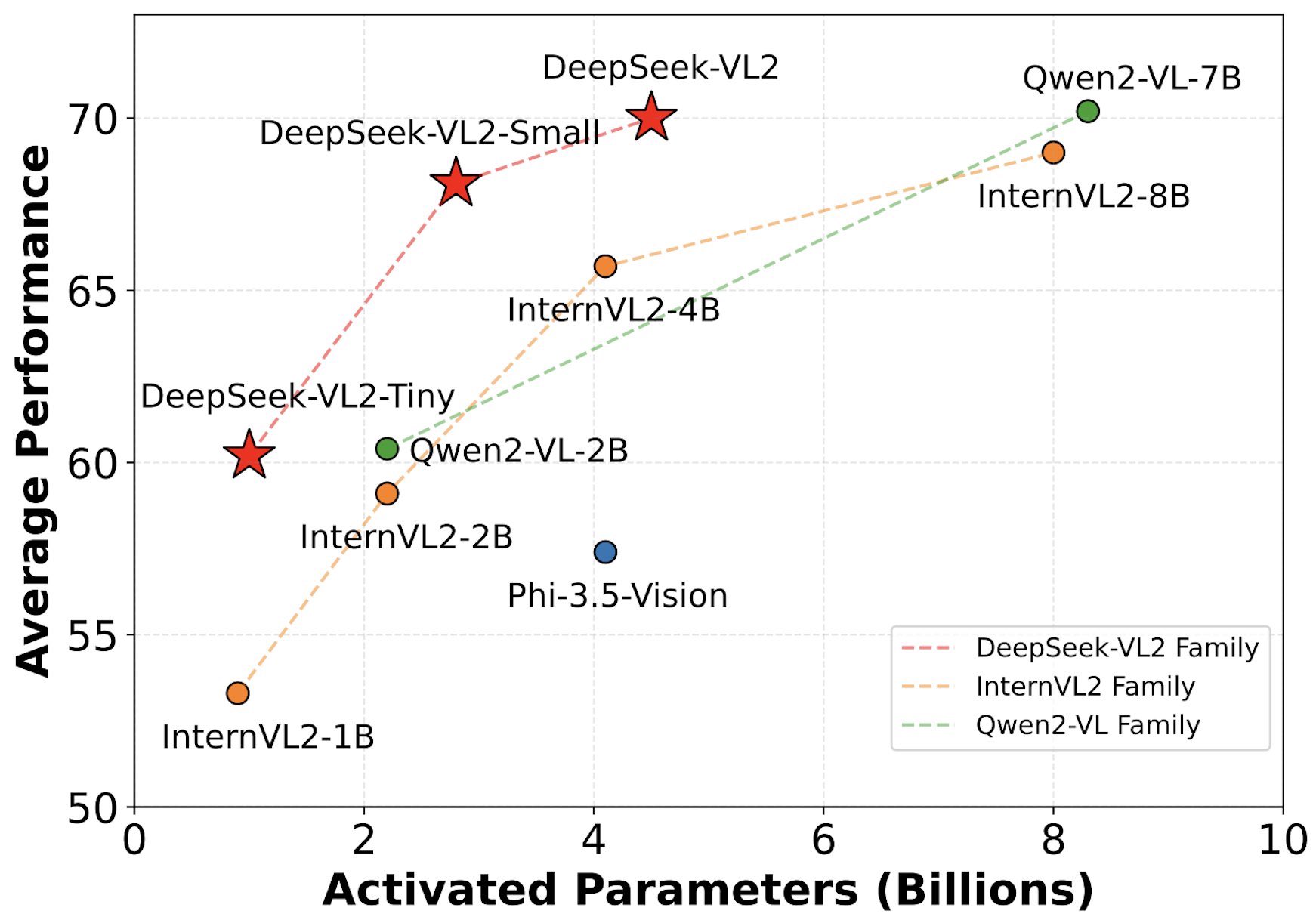
The series includes three configurations:
- DeepSeek-VL2-Tiny: 3.37 billion parameters (1.0 billion activated)
- DeepSeek-VL2-Small: 16.1 billion parameters (2.8 billion activated)
- DeepSeek-VL2: 27.5 billion parameters (4.5 billion activated)
Performance Highlights
The DeepSeek-VL2 models have shown impressive results:
- 92.3% Accuracy: Achieved in OCR tasks, outperforming many existing models.
- 15% Improvement: Enhanced precision in visual grounding tasks compared to previous models.
- 30% Reduction: In computational resources needed while maintaining high accuracy.
Key Takeaways
- Dynamic Tiling: Improves feature extraction from high-resolution images.
- Scalable Configurations: Options for lightweight to resource-intensive applications.
- Diverse Datasets: Enhance performance across various tasks.
- Sparse Computation: Reduces costs without sacrificing accuracy.
Conclusion
The DeepSeek-VL2 series sets a new benchmark in AI performance. Its innovative features allow for precise image processing and efficient text handling, excelling in tasks like OCR and visual grounding. This model series is ideal for businesses looking to leverage AI effectively.
Explore AI Solutions
To learn more about how AI can transform your business, consider these steps:
- Identify Automation Opportunities: Find areas where AI can enhance customer interactions.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and offer customization.
- Implement Gradually: Start with a pilot project, analyze results, and expand usage.
For AI KPI management advice, contact us at hello@itinai.com. Follow us for updates on Telegram or @itinaicom.


























