
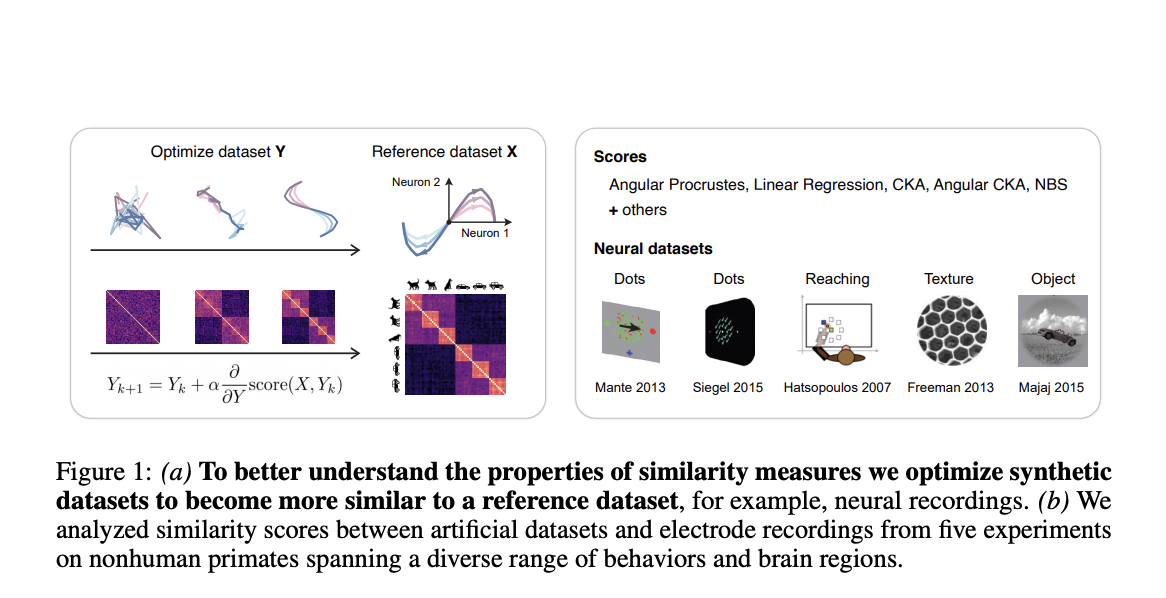
Understanding Similarity in Information Processing
To find out if two systems—biological or artificial—process information in the same way, we use various similarity measures. These include:
- Linear Regression
- Centered Kernel Alignment (CKA)
- Normalized Bures Similarity (NBS)
- Angular Procrustes Distance
While these measures are popular, understanding what makes a good similarity score is still unclear. Researchers often compare model representations with brain activity to identify brain-like features. However, it remains uncertain if these measures truly reflect the relevant computational properties, highlighting the need for clearer guidelines.
New Evaluation Framework for Similarity Measures
Recent research introduces a practical framework for selecting representational similarity measures. This framework:
- Optimizes synthetic datasets to closely match neural recordings.
- Allows systematic analysis of how different metrics prioritize various data features.
- Is model-independent, making it applicable across various neural datasets.
This approach reveals how similarity measures influence task-relevant information by starting with unstructured noise, rather than pre-trained models.
Key Findings from the Research
Researchers from MIT, NYU, and HIH Tübingen developed a tool to analyze similarity measures effectively. Their findings include:
- High similarity scores do not always indicate that task-related information is encoded similarly to neural data.
- Different metrics focus on different aspects of the data, influencing the interpretation of results.
- No consistent thresholds exist for what constitutes a “good” similarity score across datasets.
This research emphasizes caution in interpreting similarity scores when comparing models with neural systems.
Measuring Similarity Between Systems
To compare two systems, researchers analyze feature representations from brain areas or model layers by calculating similarity scores using various methods, such as:
- CKA
- Angular Procrustes
- NBS
The process involves optimizing synthetic datasets to maximize their similarity to reference datasets, revealing how well the synthetic data captures task-relevant information.
Limitations of Current Similarity Measures
The study exposes limitations in commonly used measures like CKA and linear regression:
- High similarity scores may not indicate effective encoding of task-related information.
- The quality of these scores varies based on the specific measure and dataset.
Practitioners are encouraged to interpret similarity scores carefully and understand the dynamics behind these metrics.
Stay Connected and Learn More
Check out the Paper, Project, and GitHub for more details. Follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you enjoy our work, subscribe to our newsletter. Join our community of over 55k on ML SubReddit!
Upcoming Live Webinar – Oct 29, 2024
Join us for insights on the best platform for serving fine-tuned models: Predibase Inference Engine.
Transform Your Business with AI
Discover how AI can enhance your operations:
- Identify Automation Opportunities: Find key areas for AI integration.
- Define KPIs: Measure the impact of AI on your business outcomes.
- Select AI Solutions: Choose customizable tools that meet your needs.
- Implement Gradually: Start small, gather data, and expand usage wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram at t.me/itinainews or Twitter at @itinaicom.
Explore how AI can revolutionize your sales processes and customer engagement at itinai.com.
























