
The Value of CS-Bench in Evaluating LLMs in Computer Science
Introduction
The emergence of large language models (LLMs) has shown significant potential across various fields. However, effectively utilizing computer science knowledge and enhancing LLMs’ performance remains a key challenge.
CS-Bench: A Practical Solution
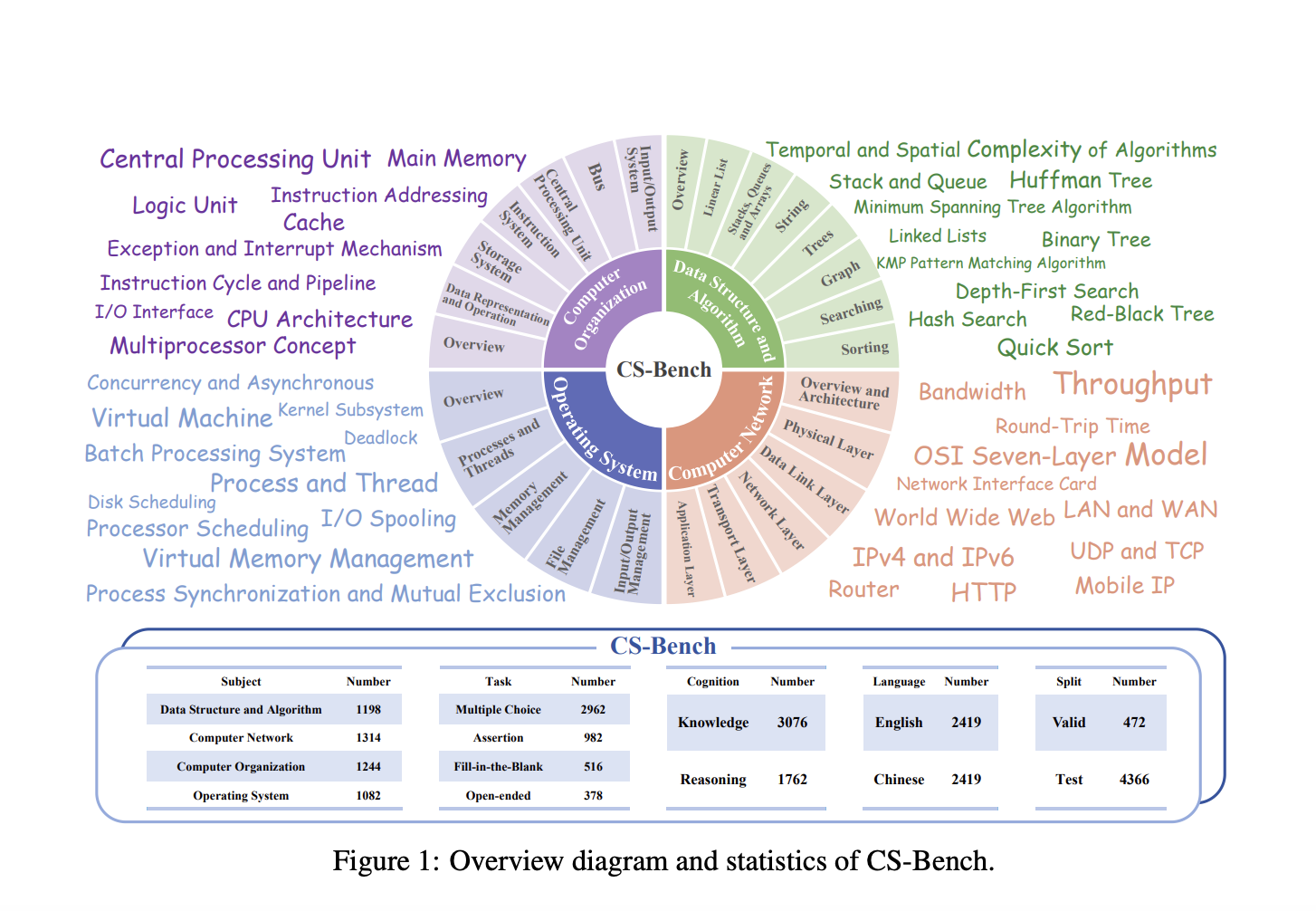
CS-Bench is the first benchmark dedicated to evaluating LLMs’ performance in computer science. It features high-quality, diverse task forms, and bilingual evaluation, comprising approximately 5,000 carefully curated test items spanning 26 sections across 4 key computer science domains.
Key Features of CS-Bench
CS-Bench covers four key domains: Data Structure and Algorithm (DSA), Computer Organization (CO), Computer Network (CN), and Operating System (OS). It includes 26 fine-grained subfields and diverse task forms to enrich assessment dimensions and simulate real-world scenarios.
Evaluation Results
Evaluation results show that overall scores of models range from 39.86% to 72.29%. GPT-4 and GPT-4o represent the highest standard on CS-Bench, being the only models exceeding 70% proficiency.
Insights and Applications
CS-Bench provides valuable insights into LLMs’ performance in computer science, offering directions for enhancing LLMs in the field and providing valuable insights into their cross-abilities and applications, paving the way for future advancements in AI and computer science.
Connect with Us
If you want to evolve your company with AI, stay competitive, and use CS-Bench for your advantage, connect with us at hello@itinai.com. For continuous insights into leveraging AI, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.


























