
Understanding Reward Modeling in AI
What is Reward Modeling?
Reward modeling is essential for aligning large language models (LLMs) with human preferences. It helps improve the quality of AI responses through a method called reinforcement learning from human feedback (RLHF). Traditional reward models assign scores to evaluate how well AI outputs match human judgments.
Challenges with Traditional Models
However, traditional reward models often lack clarity and can be vulnerable to issues like reward hacking. They also do not fully utilize the language capabilities of LLMs. A new approach, called the LLM-as-a-judge, offers critiques along with scores, making the evaluation process clearer.
Innovative Solutions
Recent advancements aim to combine traditional reward models with the LLM-as-a-judge approach. This new method generates critiques and scores together, providing better feedback. Yet, integrating these critiques into reward models is challenging due to conflicting goals and the high resources needed for training.
Self-Alignment Techniques
Self-alignment techniques use the LLM’s ability to create critiques and preference labels, offering a cost-effective alternative to human input. By merging self-generated critiques with human data, researchers improve the robustness and efficiency of reward models.
Introducing Critic-RM
Critic-RM is a framework developed by researchers from GenAI, Meta, and Georgia Institute of Technology. It enhances reward models by using self-generated critiques, removing the need for strong teacher models. The process involves generating critiques with scores and filtering them based on human preferences.
Performance Improvements
Critic-RM has shown significant improvements in reward modeling accuracy, achieving 3.7%–7.3% better results on benchmarks like RewardBench and CrossEval. It also enhances reasoning accuracy by 2.5%–3.2%, demonstrating its effectiveness across various tasks.
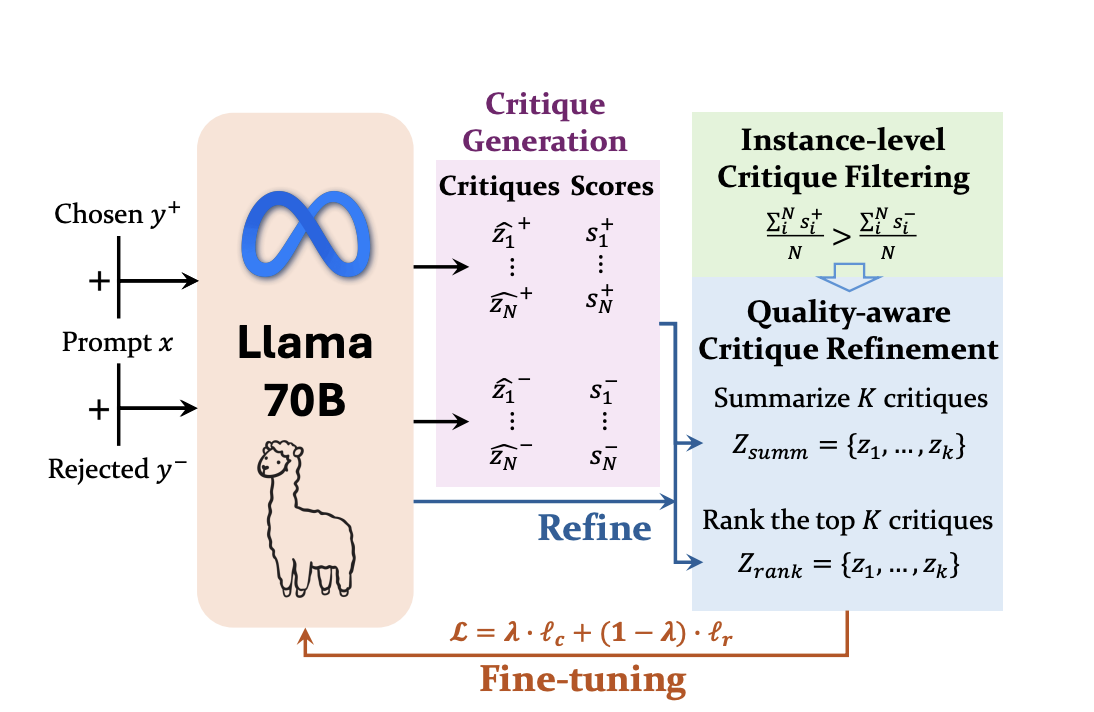
How Critic-RM Works
The Critic-RM framework generates critiques as intermediate steps between responses and final rewards. It uses a two-step process: generating critiques with a fine-tuned LLM and refining them to ensure quality. The model is trained to balance critique generation and reward prediction.
Data Utilization
The study employs both public and synthetic datasets to train reward models. These datasets cover various domains, including chat, helpfulness, reasoning, and safety. Evaluation benchmarks assess the model’s performance on preference accuracy and critique quality.
Conclusion
Critic-RM introduces a self-critiquing framework that improves reward modeling for LLMs. By generating critiques and scalar rewards, it enhances preference ranking with clear rationales. Experimental results show significant accuracy improvements, making it a valuable tool for aligning AI with human preferences.
Get Involved
Check out the research paper for more details. Follow us on Twitter, join our Telegram Channel, and LinkedIn Group for updates. If you appreciate our work, subscribe to our newsletter and join our 60k+ ML SubReddit community.
Transform Your Business with AI
To stay competitive and leverage AI effectively, consider using Critic-RM. Here’s how to get started:
– **Identify Automation Opportunities:** Find key customer interactions that can benefit from AI.
– **Define KPIs:** Ensure your AI initiatives have measurable impacts.
– **Select an AI Solution:** Choose tools that fit your needs and allow customization.
– **Implement Gradually:** Start with a pilot program, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram t.me/itinainews or Twitter @itinaicom. Discover how AI can transform your sales processes and customer engagement at itinai.com.

























