
Advancements in LLMs and Their Challenges
Large Language Models (LLMs) are transforming research and development, but their high costs make them hard to access for many. A key challenge is reducing latency in applications that require quick responses.
Understanding KV Cache
KV cache is essential for LLMs, storing key-value pairs during the inference process. It helps streamline operations by reducing complexity from quadratic to linear. However, as the size of the KV cache increases, it can overwhelm GPUs, leading to delays and reduced performance.
Addressing PCIe Limitations
Slow PCIe interfaces can significantly increase latency, causing GPUs to remain idle for extended periods. Previous attempts to improve PCIe performance often fell short due to mismatched data transfer and computation times.
Innovative Solutions from USC Researchers
Researchers at the University of Southern California have developed a new method to enhance CPU-GPU interactions for LLM inference. This approach focuses on optimizing PCIe usage through:
Efficient KV Cache Management
Instead of transferring the entire KV cache, the method sends smaller segments to the GPU, which then reconstructs the full cache. This minimizes information loss while improving efficiency.
Three Key Modules
- Profiler Module: Gathers hardware data like PCIe bandwidth and GPU speed.
- Scheduler Module: Uses linear programming to find the best KV split point, maximizing the overlap of computation and communication.
- Runtime Module: Manages data transfer and memory allocation between CPU and GPU.
Optimizing Execution Plans
The Scheduler Module employs two strategies:
- Row-by-Row Schedule: Reduces latency by allowing the GPU to start reconstructing the KV cache while loading other activations.
- Column-by-Column Schedule: Enhances throughput by reusing model weights across batches, overlapping data transmission with computation.
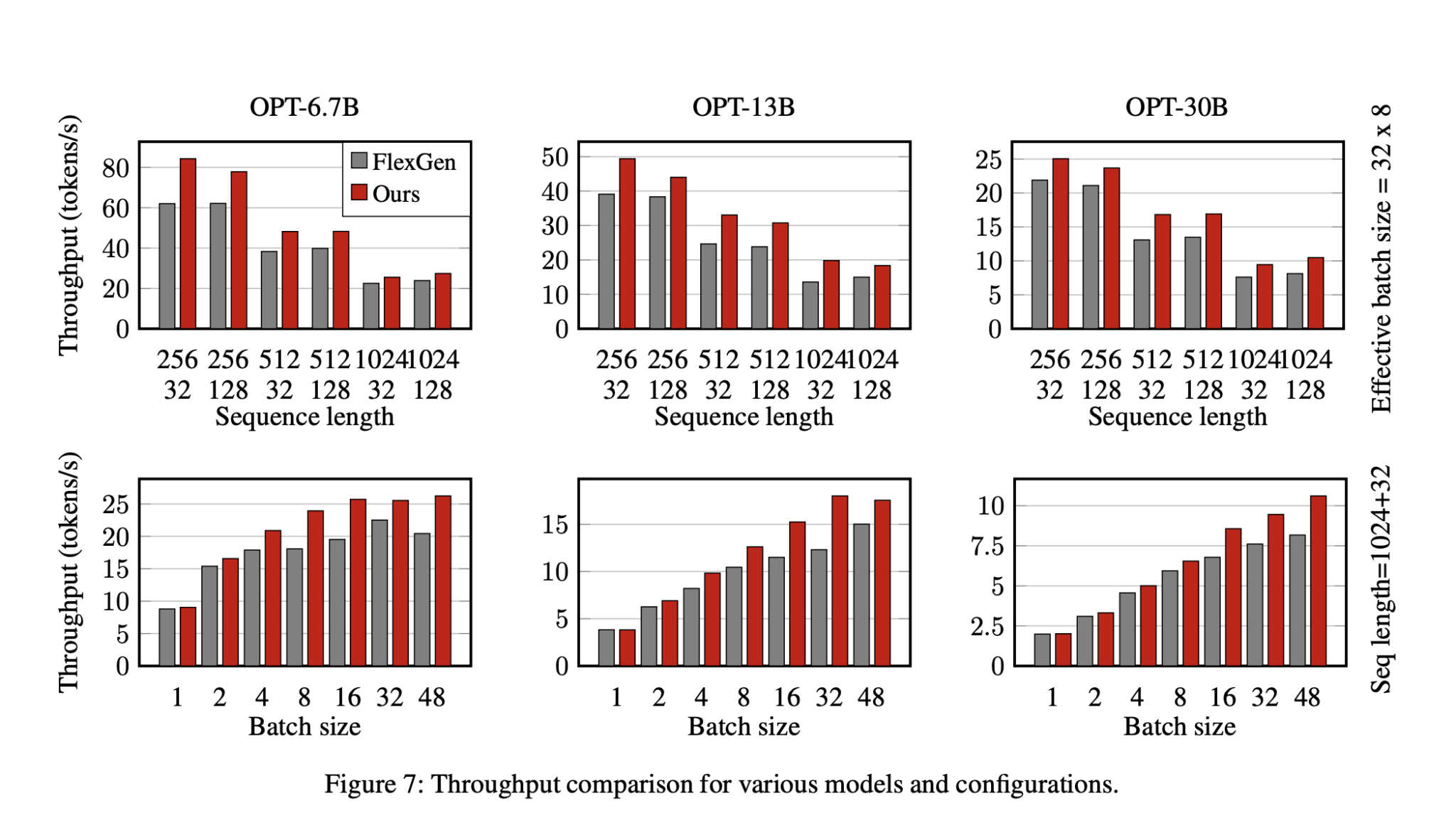
Performance Results
Testing on an NVIDIA A100 GPU showed significant improvements:
- Latency Reduction: 35.8% lower latency compared to traditional methods.
- Throughput Improvement: Up to 29% better throughput than baseline performance.
Conclusion
This innovative CPU-GPU I/O-aware method effectively reduces latency and boosts throughput in LLM inference, making AI solutions more efficient.
Get Involved
For more insights, follow us on Twitter, join our Telegram Channel, and connect on LinkedIn. If you’re interested in evolving your company with AI, explore how this technology can enhance your operations:
- Identify Automation Opportunities: Find areas in customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI initiatives have measurable impacts.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start small, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. Stay updated on AI insights via our Telegram at t.me/itinainews or follow us on Twitter @itinaicom.
Discover how AI can transform your sales processes and customer engagement at itinai.com.


















![Exploring Well-Designed Machine Learning (ML) Codebases [Discussion]](https://itinai.com/wp-content/uploads/2025/03/itinai.com_russian_handsome_charismatic_models_scrum_site_dev_96579955-dded-4288-b857-3ee0b72c8d7a_2.png)

